我正试图理解 faster rcnn 中的区域建议网络。我明白它在做什么,但我仍然不明白训练是如何进行的,特别是其中的细节。
假设我们使用 VGG16 最后一层,形状为 14x14x512(在 maxpool 之前和 228x228 的图片),以及 k=9 种不同的锚点。推断时,我想预测 9*2 类标签和 9*4 个边界框坐标。我的中间层是一个 512 维向量。
(图像显示来自 ZF 网络的 256 个)
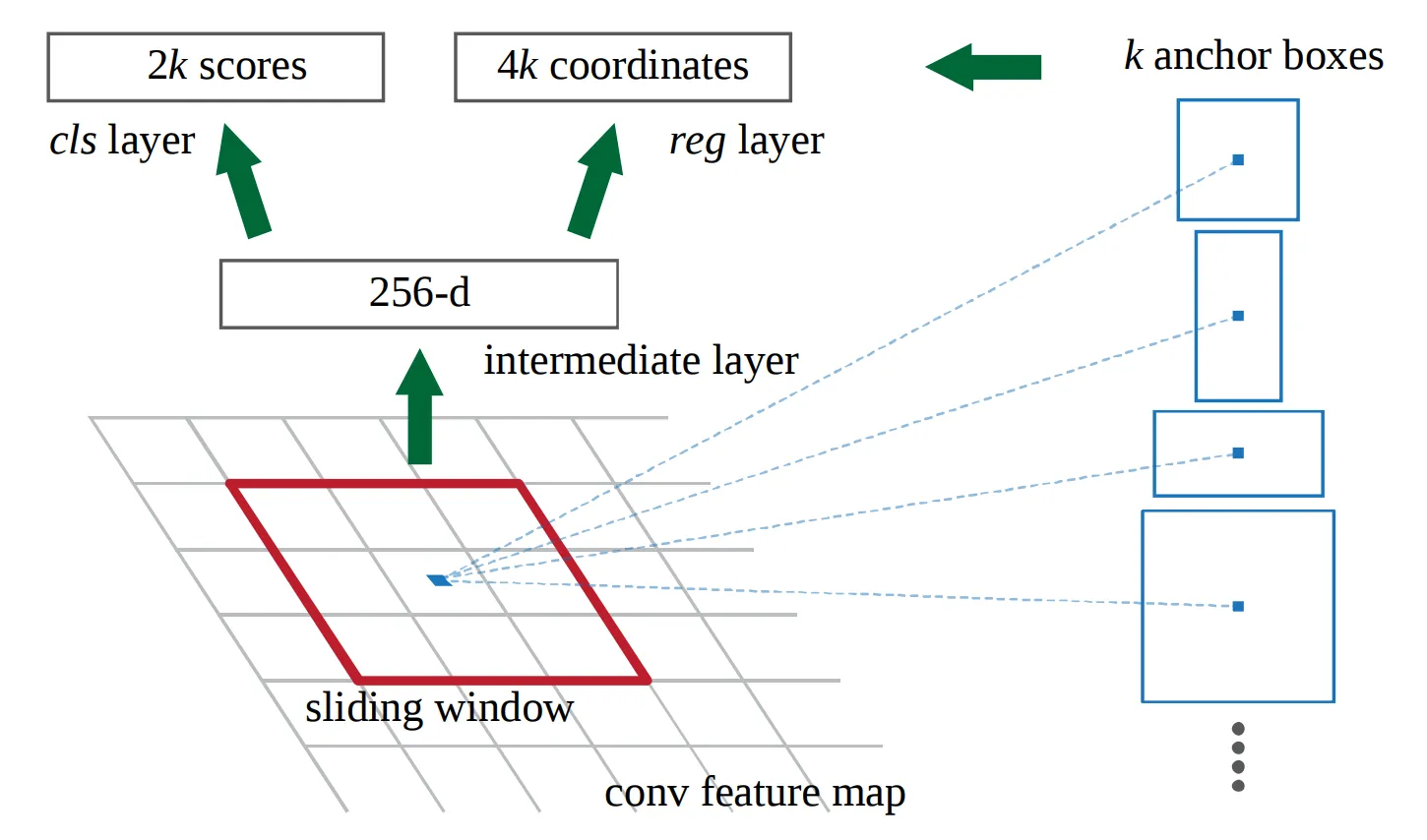
在论文中,他们写道:
“我们在图像中随机采样 256 个锚点来计算 mini-batch 的损失函数,其中采样的正锚点和负锚点的比例最多为 1:1”
这就是我不确定的部分。这是否意味着对于每一种 9(k) 种锚点类型,具体的分类器和回归器仅使用包含该类型正负锚点的 minibatch 进行训练?
这样,我基本上会在中间层中使用共享权重训练 k 个不同的网络吗?因此,每个 minibatch 将包含训练数据 x=卷积特征图的 3x3x512 滑动窗口和 y=该特定锚点类型的 ground truth。推断时,我将它们全部组合起来。
感谢您的帮助。