我正在尝试从音频(.wav文件)中提取MFCC特征,我已经尝试了python_speech_features和librosa,但它们给出的结果完全不同:
audio, sr = librosa.load(file, sr=None)
# librosa
hop_length = int(sr/100)
n_fft = int(sr/40)
features_librosa = librosa.feature.mfcc(audio, sr, n_mfcc=13, hop_length=hop_length, n_fft=n_fft)
# psf
features_psf = mfcc(audio, sr, numcep=13, winlen=0.025, winstep=0.01)
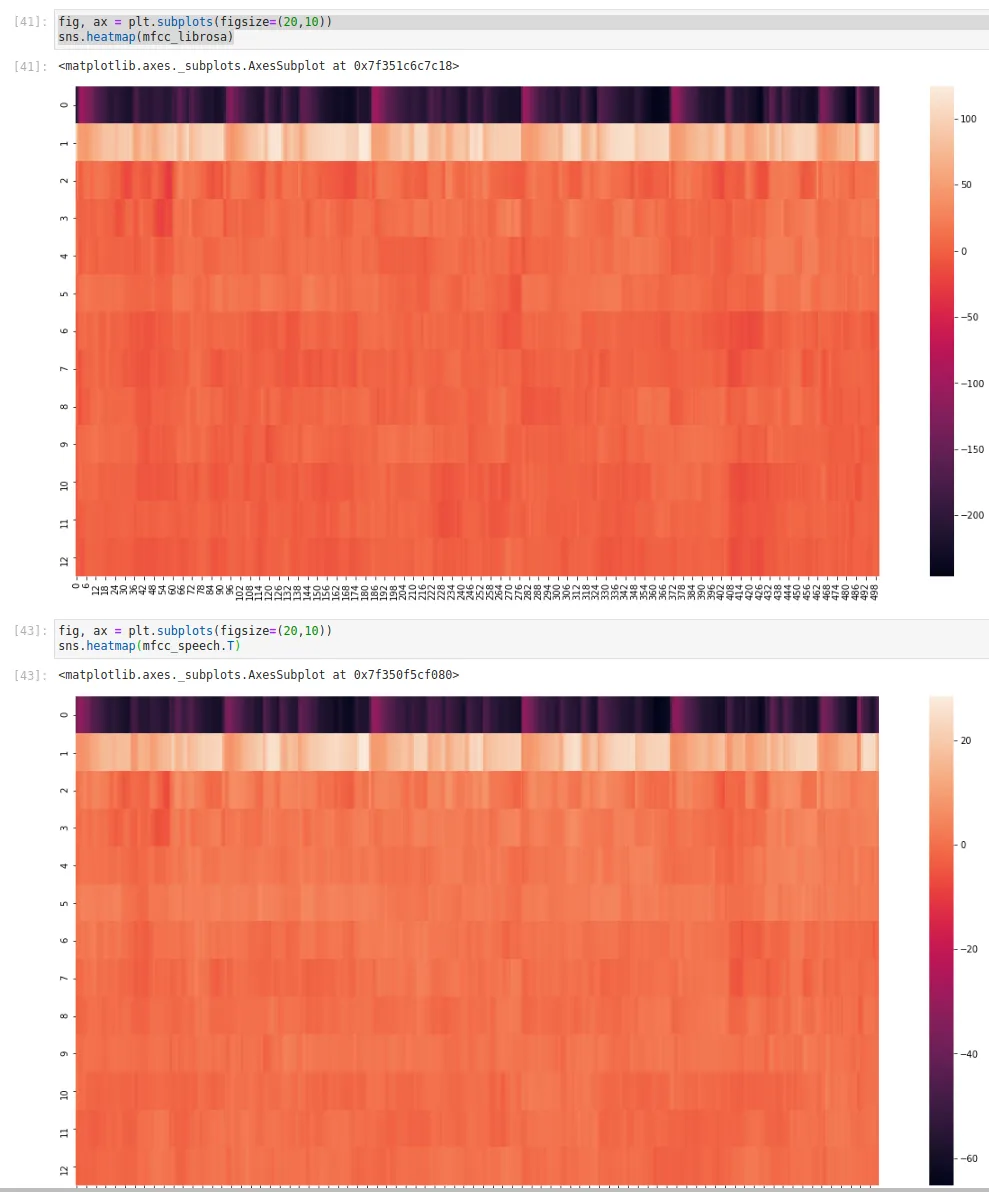
以下是图表: librosa:
 python_speech_features:
python_speech_features:
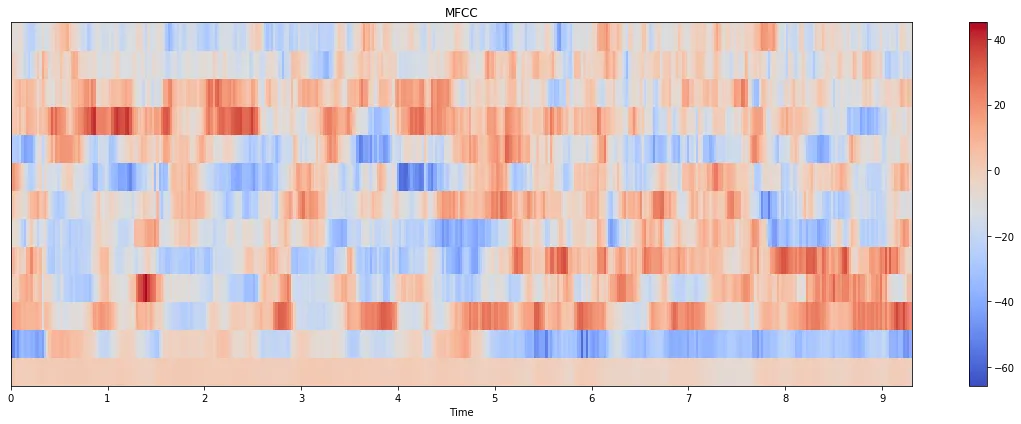 我有没有为这两种方法传递错误的参数?为什么会有这么大的差异?
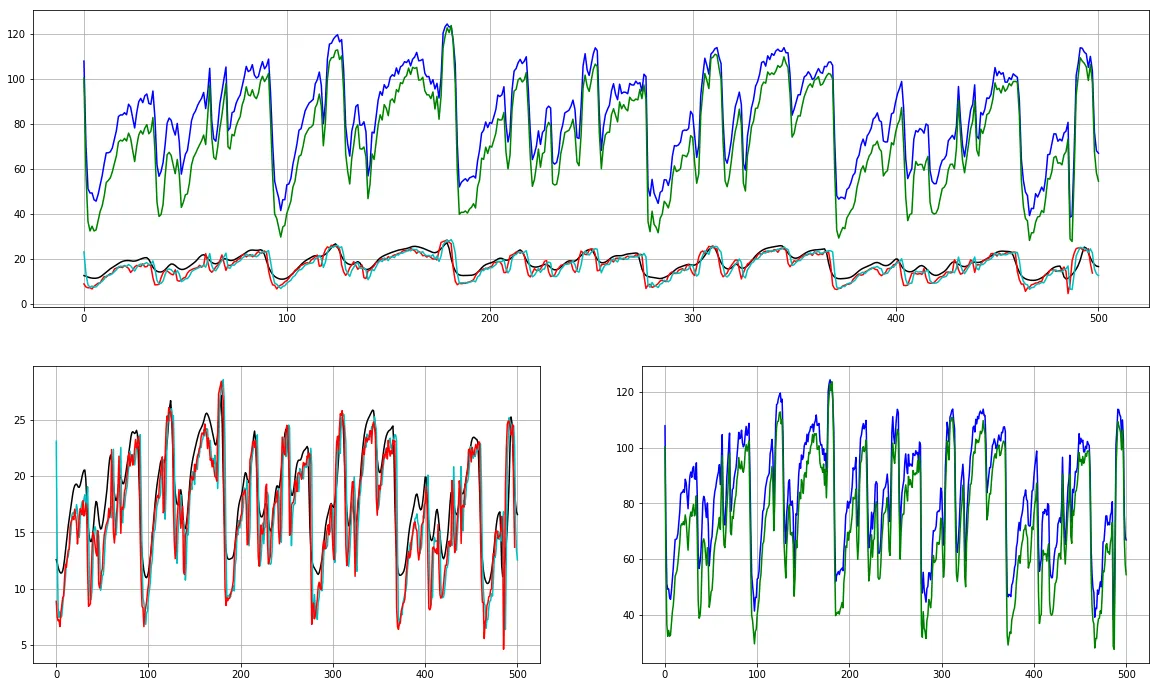
我有没有为这两种方法传递错误的参数?为什么会有这么大的差异?更新:我也尝试了tensorflow.signal实现,以下是结果:
 图表本身更接近于librosa,但比例更接近于python_speech_features。(请注意,这里计算了80个mel bin并选取了前13个;如果只使用13个bin进行计算,则结果看起来会非常不同)。下面是代码:
图表本身更接近于librosa,但比例更接近于python_speech_features。(请注意,这里计算了80个mel bin并选取了前13个;如果只使用13个bin进行计算,则结果看起来会非常不同)。下面是代码:stfts = tf.signal.stft(audio, frame_length=n_fft, frame_step=hop_length, fft_length=512)
spectrograms = tf.abs(stfts)
num_spectrogram_bins = stfts.shape[-1]
lower_edge_hertz, upper_edge_hertz, num_mel_bins = 80.0, 7600.0, 80
linear_to_mel_weight_matrix = tf.signal.linear_to_mel_weight_matrix(
num_mel_bins, num_spectrogram_bins, sr, lower_edge_hertz, upper_edge_hertz)
mel_spectrograms = tf.tensordot(spectrograms, linear_to_mel_weight_matrix, 1)
mel_spectrograms.set_shape(spectrograms.shape[:-1].concatenate(linear_to_mel_weight_matrix.shape[-1:]))
log_mel_spectrograms = tf.math.log(mel_spectrograms + 1e-6)
features_tf = tf.signal.mfccs_from_log_mel_spectrograms(log_mel_spectrograms)[..., :13]
features_tf = np.array(features_tf).T
我认为我的问题是:哪一个输出更接近于MFCC的实际样貌?
samplerate=sr,会有什么不同吗?或者在librosa版本中更改dct_type呢? - Hendriksr作为输入。在dct_type方面,当我将其设置为3时,有一些变化,但仍然与psf输出相差甚远(1和2几乎相同)。 - TYZsamplerate=sr,会有所不同吗?我的意思是,您正在将其作为位置参数传递,但它是一个关键字参数。不确定在这里将其作为kwarg参数传递是否有所不同,但我会遵守(显式)API。 - Hendrik