在std::string的上下文中,SSO缩写的意思是什么?
5
背景/概述
自动变量(从栈中创建的变量,即不调用malloc/new创建的变量)的操作通常比涉及自由存储区(使用new创建的变量)的操作要快得多。但是,自动数组的大小在编译时固定,而来自自由存储区的数组的大小则不固定。此外,堆栈大小受限(通常为几个 MiB),而自由存储区仅受系统内存限制。
SSO 是短字符串优化。一个std::string通常将字符串存储为指向自由存储区("堆")的指针,这给出了类似于调用new char [size]的性能特征。 这可以防止非常大的字符串导致堆栈溢出,但对于复制操作可能会更慢。作为一种优化,许多std::string实现会创建一个小的自动数组,例如char [20]。如果您有一个长度小于等于20个字符的字符串(根据此示例,实际大小会有所变化),它会直接存储在该数组中。这避免了完全调用new的需要,从而加快了速度。
编辑:
我没有预料到这个答案会如此受欢迎,但既然如此,让我给出一个更现实的实现,但要注意我从未真正阅读过 SSO 的任何实现。
实现细节
std::string至少需要存储以下信息:
- 大小
- 容量
- 数据位置
大小可以存储为std::string::size_type 或指向末尾的指针。唯一的区别在于您是想在用户调用size时必须减去两个指针还是在用户调用end时必须将size_type加到指针上。容量也可以以这两种方式之一存储。
你所不使用的部分不需要付出代价。
首先,考虑基于我上面概述的 Naive 实现:
class string {
public:
// all 83 member functions
private:
std::unique_ptr<char[]> m_data;
size_type m_size;
size_type m_capacity;
std::array<char, 16> m_sso;
};
对于一个64位系统,这通常意味着每个字符串的std::string有24字节的“开销”,再加上SSO缓冲区的16字节(由于填充要求,这里选择16而不是20)。在我的简化示例中,将那三个数据成员和本地字符数组存储起来并不是很明智。如果m_size <= 16,那么我会将所有数据存储在m_sso中,因此我已经知道容量,不需要指向数据的指针。如果m_size > 16,则我不需要m_sso。绝对没有重叠的情况下我需要它们全部。一个更聪明、不浪费空间的解决方案看起来会像这样(未经测试,仅供示例):
class string {
public:
// all 83 member functions
private:
size_type m_size;
union {
class {
// This is probably better designed as an array-like class
std::unique_ptr<char[]> m_data;
size_type m_capacity;
} m_large;
std::array<char, sizeof(m_large)> m_small;
};
};
我会认为大多数实现看起来更像这样。
4
std::string const &时,获取数据只需要进行单个内存间接引用,因为数据存储在引用位置。如果没有小字符串优化,访问数据将需要进行两次内存间接引用(首先加载字符串的引用并读取其内容,然后第二次读取字符串中数据指针的内容)。 - David Stone正如其他答案已经解释的那样,SSO表示"Small/Short String Optimization"(小字符串/短字符串优化)。这种优化的动机是不可否认的证据表明,应用程序通常处理的字符串要比长字符串短得多。
正如David Stone在他上面的回答中所解释的那样,std::string类使用一个内部缓冲区来存储内容,直到给定长度为止,这消除了动态分配内存的需要。这使代码更高效和更快。
这个相关的答案清楚地显示,内部缓冲区的大小取决于std::string的实现,这因平台而异(请参见下面的基准测试结果)。
基准测试
下面是一个小程序,对具有相同长度的大量字符串进行复制操作的基准测试。 它开始打印复制1千万个长度为1的字符串所需的时间。 然后,它会重复使用长度为2的字符串。一直进行下去,直到长度达到50。
#include <string>
#include <iostream>
#include <vector>
#include <chrono>
static const char CHARS[] = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
static const int ARRAY_SIZE = sizeof(CHARS) - 1;
static const int BENCHMARK_SIZE = 10000000;
static const int MAX_STRING_LENGTH = 50;
using time_point = std::chrono::high_resolution_clock::time_point;
void benchmark(std::vector<std::string>& list) {
std::chrono::high_resolution_clock::time_point t1 = std::chrono::high_resolution_clock::now();
// force a copy of each string in the loop iteration
for (const auto s : list) {
std::cout << s;
}
std::chrono::high_resolution_clock::time_point t2 = std::chrono::high_resolution_clock::now();
const auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1).count();
std::cerr << list[0].length() << ',' << duration << '\n';
}
void addRandomString(std::vector<std::string>& list, const int length) {
std::string s(length, 0);
for (int i = 0; i < length; ++i) {
s[i] = CHARS[rand() % ARRAY_SIZE];
}
list.push_back(s);
}
int main() {
std::cerr << "length,time\n";
for (int length = 1; length <= MAX_STRING_LENGTH; length++) {
std::vector<std::string> list;
for (int i = 0; i < BENCHMARK_SIZE; i++) {
addRandomString(list, length);
}
benchmark(list);
}
return 0;
}
如果您想运行此程序,应该像这样执行:./a.out > /dev/null,这样打印字符串的时间就不会被计算。
重要的数字将被打印到stderr中,因此它们将显示在控制台中。
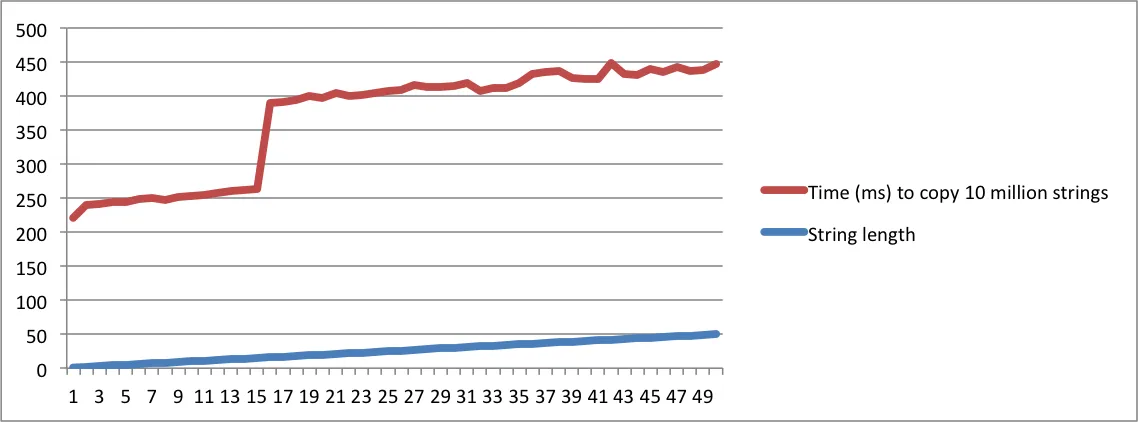
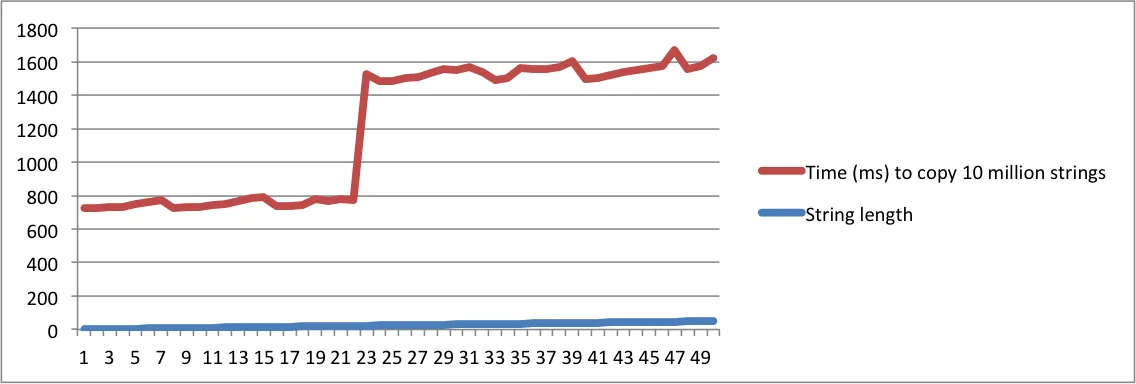
我已经使用我的MacBook和Ubuntu机器的输出创建了图表。请注意,当长度达到一定点时,复制字符串所需的时间会大幅增加。那是字符串不再适合内部缓冲区并且必须使用内存分配的时刻。
还要注意,在Linux机器上,跳变发生在字符串长度达到16时。在Macbook上,跳变发生在长度达到23时。这证实了SSO取决于平台实现。
Ubuntu
Macbook Pro
1
SSO是“Small String Optimization”的缩写,这是一种技术,在该技术中,小字符串被嵌入到字符串类的主体中,而不是使用单独分配的缓冲区。
原文链接
- 相关问题
- 11 在constexpr上下文中,std::array指针的size()是多少?
- 9 在constexpr上下文中使用std::optional赋值运算符
- 6 在constexpr上下文中,任何类中包含std::string的std::variant都无法编译通过。
- 3 在字符串文字的上下文中,'R' 是什么意思?
- 3 禁用std:string的SSO
- 23 在Lambda表达式的上下文中,“capture”一词是什么意思?
- 5 std::move(std::unique_ptr())组合的标准缩写是什么?
- 4 在非const上下文中使用std::size
- 25 declval<_Xp(&)()>()() - 在下面的上下文中,这句话是什么意思?
- 4 在这个上下文中,“忽略模板参数上的属性”是什么意思?