我也对使用线性排名选择(有时也称为“排名选择”)计算概率的不同来源感到有些困惑,至少我希望这两个术语指的是同一件事情。对我来说比较难理解的部分是排名之和,在大多数来源中似乎已被省略或至少没有明确说明。下面我将介绍一个简短但详细的 Python 示例,展示如何计算概率分布(通常看到的漂亮图表)。假设以下是一些个体适应度的示例值:10、9、3、15、85、7。排序后,按升序分配排名:第1名:3,第2名:7,第3名:9,第4名:10,第5名:15,第6名:85。所有排名之和为1+2+3+4+5+6,即
21,也可以使用高斯公式(6+1)×6/2进行计算。
因此,我们计算出的概率是:1/21、2/21、3/21、4/21、5/21、6/21,你可以将其表示为百分比:
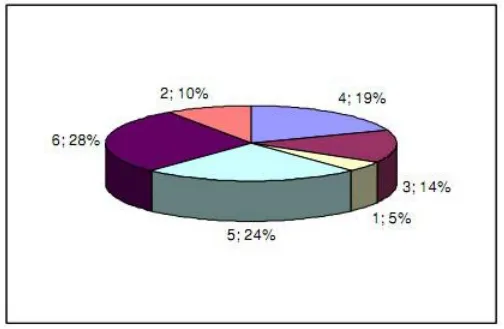
请注意,这并不是遗传算法实际实现中所使用的内容,仅是一个帮助脚本,以便让您更好地理解。
您可以使用以下命令获取此脚本:
curl -o ranksel.py https://gist.githubusercontent.com/kburnik/3fe766b65f7f7427d3423d233d02cd39/raw/5c2e569189eca48212c34b3ea8a8328cb8d07ea5/ranksel.py
"""
Assumed name of script: ranksel.py
Sample program to estimate individual's selection probability using the Linear
Ranking Selection algorithm - a selection method in the field of Genetic
Algorithms. This should work with Python 2.7 and 3.5+.
Usage:
./ranksel.py f1 f2 ... fN
Where fK is the scalar fitness of the Kth individual. Any ordering is accepted.
Example:
$ python -u ranksel.py 10 9 3 15 85 7
Rank Fitness Sel.prob.
1 3.00 4.76%
2 7.00 9.52%
3 9.00 14.29%
4 10.00 19.05%
5 15.00 23.81%
6 85.00 28.57%
"""
from __future__ import print_function
import sys
def compute_sel_prob(population_fitness):
"""Computes and generates tuples of (rank, individual_fitness,
selection_probability) for each individual's fitness, using the Linear
Ranking Selection algorithm."""
n = len(population_fitness)
rank_sum = n * (n + 1) / 2
for rank, ind_fitness in enumerate(sorted(population_fitness), 1):
yield rank, ind_fitness, float(rank) / rank_sum
if __name__ == "__main__":
population_fitness = list(map(float, sys.argv[1:]))
print ("Rank Fitness Sel.prob.")
for rank, ind_fitness, sel_prob in compute_sel_prob(population_fitness):
print("%4d %7.2f %8.2f%%" % (rank, ind_fitness, sel_prob * 100))
{kind=link}