我有一台4个GPU的机器,在上面使用Keras运行Tensorflow(GPU版本)。我的一些分类问题需要几个小时才能完成。
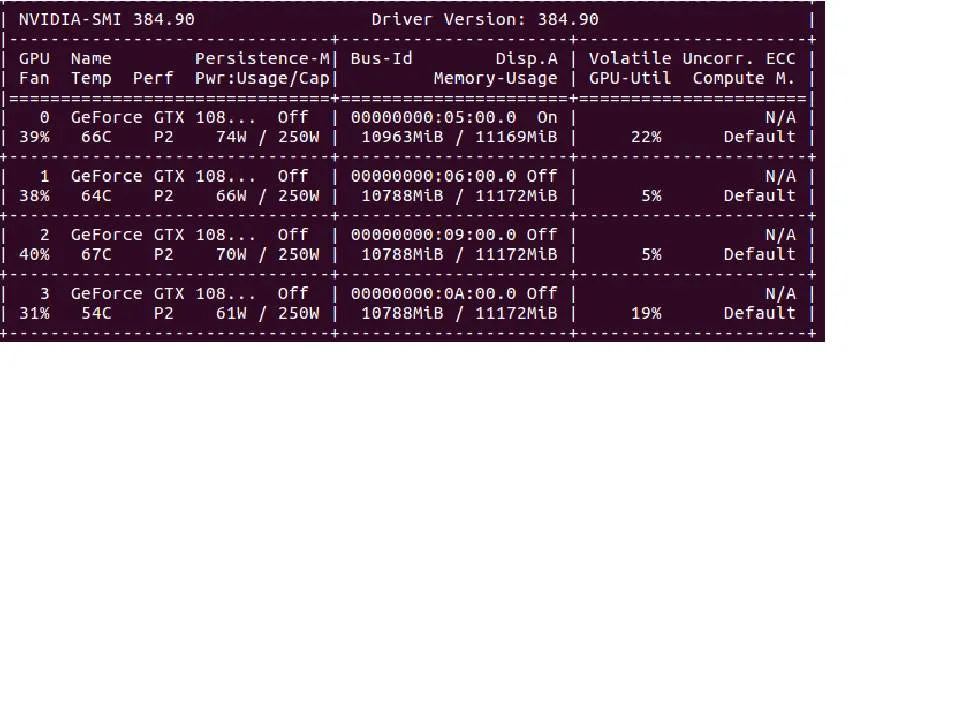
nvidia-smi命令返回Volatile GPU-Util,但任何一个GPU的利用率都不会超过25%。如何提高GPU利用率和加速训练?
我有一台4个GPU的机器,在上面使用Keras运行Tensorflow(GPU版本)。我的一些分类问题需要几个小时才能完成。
nvidia-smi命令返回Volatile GPU-Util,但任何一个GPU的利用率都不会超过25%。如何提高GPU利用率和加速训练?
如果您的GPU利用率低于80%,通常这是输入管道瓶颈的迹象。这意味着GPU大部分时间处于空闲状态,等待CPU准备数据: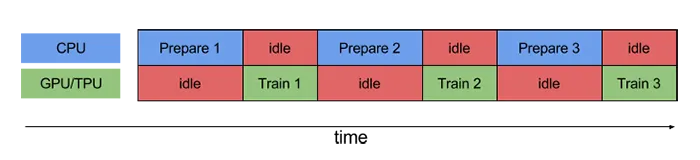
您想要的是在GPU进行训练时,CPU继续准备批处理的数据以保持GPU充电。这称为预取: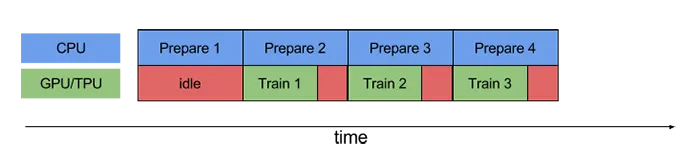
但是,如果批处理仍然比模型训练时间长得多,GPU仍将处于空闲状态,等待CPU完成下一批次。为了加快批处理速度,我们可以并行化不同的预处理操作:
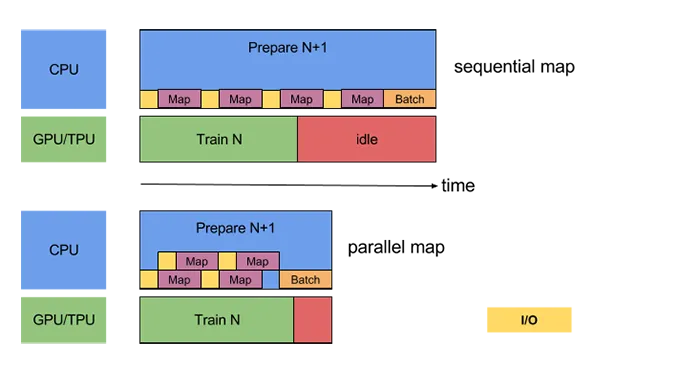
我们甚至可以通过并行化I / O来进一步优化:
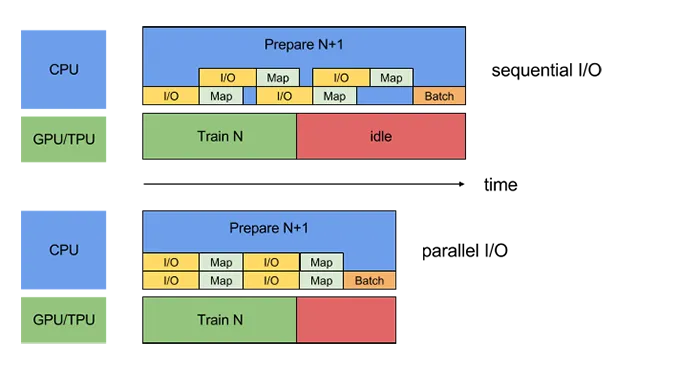
现在,要在Keras中实现此操作,您需要使用Tensorflow Data API和Tensorflow版本> = 1.9.0。这里是一个例子:
假设为了简单起见,您有两个numpy数组x和y。您可以对任何类型的数据使用tf.data,但这更容易理解。
def preprocessing(x, y):
# Can only contain TF operations
...
return x, y
dataset = tf.data.Dataset.from_tensor_slices((x, y)) # Creates a dataset object
dataset = dataset.map(preprocessing, num_parallel_calls=64) # parallel preprocessing
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(None) # Will automatically prefetch batches
....
model = tf.keras.model(...)
model.fit(x=dataset) # Since tf 1.9.0 you can pass a dataset object
tf.data非常灵活,但是和TensorFlow中的其他内容(除了eager外)一样,它使用静态图。有时候这可能会很麻烦,但加速效果是值得的。
如果想进一步了解,可以查看性能指南和TensorFlow数据指南。
ImageDataGenerator,结果发现这是瓶颈。当我将fit_generator方法中默认值1个worker的数量增加到所有可用的CPU时,训练时间迅速下降。
您也可以将数据加载到内存中,然后使用flow方法准备具有增强图像的批处理。
flow_from_directory,但是工作线程数是通过fit_generator方法的参数设置的。对此我感到抱歉,我会更新我的上面的答案。 - Konrad