我看到类似这样的内容:
我看到类似这样的内容:
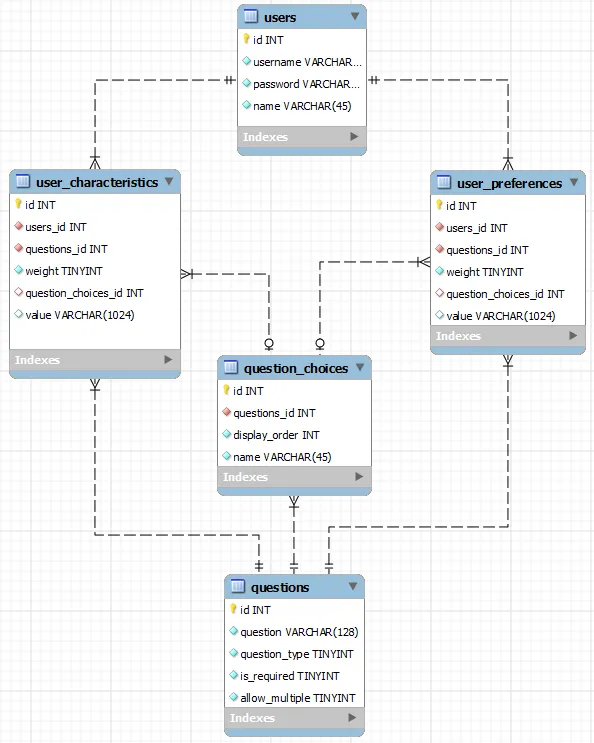
questions是问题列表,需要回答。
question_type是一个枚举值,表示期望的答案类型(例如从
question_choices中查找、日期、数字、文本等)- 无论您期望输入哪些数据类型。这个以及表格中的其他列可以驱动您的输入表单。
question_answers包含预定义的问题答案列表(例如预定义的宗教、发色或眼睛颜色列表等)。这可以用于在您的输入表单上构建下拉值列表。
users相当容易理解。
user_characteristics 包含了我对问卷的回答列表。 weight 列指示了寻找我的人拥有相同答案的重要程度。如果答案来自于 question_choices 表中构建的选择列表,则 question_choices_id 将被填充。否则,question_choices_id 将为 NULL。对于 value 列,情况恰好相反。如果答案来自于 question_choices 表中构建的选择列表,则 value 将为 NULL。否则,value 将包含用户手工回答的问题。
user_preferences 包含了我寻找的对象对问卷的回答。 weight 列指示了对于我来说,拥有相同答案的人的重要程度。question_choices_id 和 value 列与 user_characteristics 表中的行为相同。
查找我的匹配项的 SQL 可能如下所示:
SELECT uc.id
,SUM(up.weight) AS my_weighted_score_of_them
,SUM(uc.weight) AS their_weighted_score_of_me
,SUM(up.weight) + SUM(uc.weight) AS combined_weighted_score
FROM user_preferences up
JOIN user_characteristics uc
ON uc.questions_id = up.questions_id
AND uc.question_choices_id = up.question_choices_id
AND uc.value = up.value
AND uc.users_id != up.users_id
WHERE up.users_id = me.id
GROUP BY uc.id
ORDER BY SUM(up.weight) + SUM(uc.weight) DESC
,SUM(up.weight) DESC
,SUM(uc.weight) DESC
为了提高性能,建议在user_characteristics(id, question_id, question_choices_id, value, and user_id)和user_preferences(id, question_id, question_choices_id, value, and user_id)上创建索引。
请注意,上述SQL语句将为除发出请求的用户之外的每个用户返回一行。这显然是不可取的。因此,可以考虑添加HAVING SUM(up.weight) + SUM(uc.weight) > :some_minimum_value或其他方式进一步过滤结果。
进一步的调整可能包括仅返回将答案视为与我的偏好权重相同或更重要的人(即其特征权重>=我的权重偏好权重)。