我有一个Firehose流,旨在从不同来源和不同事件类型中摄取数百万个事件。该流应将所有数据传递到一个S3存储桶中,作为未经处理的原始数据。
我考虑根据嵌入在事件消息中的元数据,如事件源、事件类型和事件日期,在S3中对这些数据进行分区。
然而,Firehose遵循其默认的基于记录到达时间的分区方式。是否可以自定义此分区行为以符合我的需求?
更新:已接受的答案已更新,因为有一个新答案表明,该功能从2021年9月开始提供。
我有一个Firehose流,旨在从不同来源和不同事件类型中摄取数百万个事件。该流应将所有数据传递到一个S3存储桶中,作为未经处理的原始数据。
我考虑根据嵌入在事件消息中的元数据,如事件源、事件类型和事件日期,在S3中对这些数据进行分区。
然而,Firehose遵循其默认的基于记录到达时间的分区方式。是否可以自定义此分区行为以符合我的需求?
更新:已接受的答案已更新,因为有一个新答案表明,该功能从2021年9月开始提供。
写这篇文章时,Vlad提到的动态分区功能仍然很新。我需要它成为CloudFormation模板的一部分,但它还没有得到适当的文档支持。我不得不添加DynamicPartitioningConfiguration才能使其正常工作。MetadataExtractionQuery语法也没有得到适当的文档支持。
MyKinesisFirehoseStream:
Type: AWS::KinesisFirehose::DeliveryStream
...
Properties:
ExtendedS3DestinationConfiguration:
Prefix: "clients/client_id=!{client_id}/dt=!{timestamp:yyyy-MM-dd}/"
ErrorOutputPrefix: "errors/!{firehose:error-output-type}/"
DynamicPartitioningConfiguration:
Enabled: "true"
RetryOptions:
DurationInSeconds: "300"
ProcessingConfiguration:
Enabled: "true"
Processors:
- Type: AppendDelimiterToRecord
- Type: MetadataExtraction
Parameters:
- ParameterName: MetadataExtractionQuery
ParameterValue: "{client_id:.client_id}"
- ParameterName: JsonParsingEngine
ParameterValue: JQ-1.6
前缀:"clients/client_id=!{partitionKeyFromQuery:client_id}/dt=!{timestamp:yyyy-MM-dd}/",也许对其他人有用。 - Gabriele前缀:"clients/client_id=!{partitionKeyFromQuery:client_id}/dt=!{timestamp:yyyy-MM-dd}/",也许对其他人有用。 - undefined
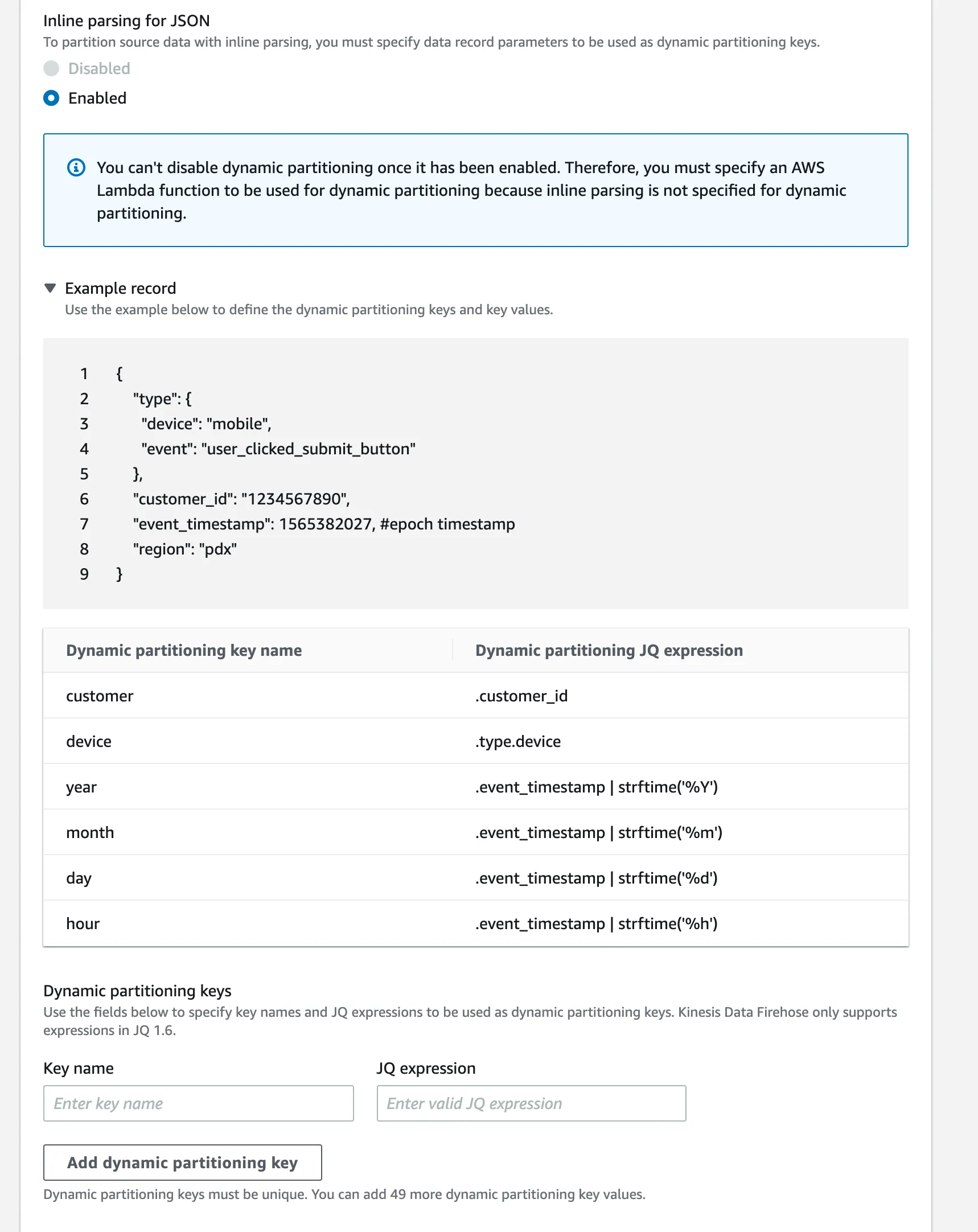
不行,你不能基于事件内容进行“分区”。
一些选项是:
如果您要将输出与Amazon Athena或Amazon EMR一起使用,则还可以考虑将其转换为Parquet格式,这具有更好的性能。这需要对S3中的数据进行批处理后处理,而不是在流中到达时转换数据。
{
"data":
{
"timestamp":1633521266990,
"defaultTopic":"Topic",
"data":
{
"OUT1":"Inactive",
"Current_mA":3.92
}
}
}
const DeliveryStream = new CfnDeliveryStream(this, 'deliverystream', {
deliveryStreamName: 'deliverystream',
extendedS3DestinationConfiguration: {
cloudWatchLoggingOptions: {
enabled: true,
},
bucketArn: Bucket.bucketArn,
roleArn: deliveryStreamRole.roleArn,
prefix: 'defaultTopic=!{partitionKeyFromQuery:defaultTopic}/!{timestamp:yyyy/MM/dd}/',
errorOutputPrefix: 'error/!{firehose:error-output-type}/',
bufferingHints: {
intervalInSeconds: 60,
},
dynamicPartitioningConfiguration: {
enabled: true,
},
processingConfiguration: {
enabled: true,
processors: [
{
type: 'MetadataExtraction',
parameters: [
{
parameterName: 'MetadataExtractionQuery',
parameterValue: '{Topic: .data.defaultTopic}',
},
{
parameterName: 'JsonParsingEngine',
parameterValue: 'JQ-1.6',
},
],
},
{
type: 'AppendDelimiterToRecord',
parameters: [
{
parameterName: 'Delimiter',
parameterValue: '\\n',
},
],
},
],
},
},
})
我的场景是:
Firehose需要将数据发送到与Glue表绑定的S3,使用Parquet格式,并启用动态分区,因为我想从我推送到Firehose的数据中考虑年、月和日,而不是默认值。
以下是可行的代码:
rawdataFirehose:
Type: AWS::KinesisFirehose::DeliveryStream
Properties:
DeliveryStreamName: !Join ["-", [rawdata, !Ref AWS::StackName]]
DeliveryStreamType: DirectPut
ExtendedS3DestinationConfiguration:
BucketARN: !GetAtt rawdataS3bucket.Arn
Prefix: parquetdata/year=!{partitionKeyFromQuery:year}/month=!{partitionKeyFromQuery:month}/day=!{partitionKeyFromQuery:day}/
BufferingHints:
IntervalInSeconds: 300
SizeInMBs: 128
ErrorOutputPrefix: errors/
RoleARN: !GetAtt FirehoseRole.Arn
DynamicPartitioningConfiguration:
Enabled: true
ProcessingConfiguration:
Enabled: true
Processors:
- Type: MetadataExtraction
Parameters:
- ParameterName: MetadataExtractionQuery
ParameterValue: "{year:.year,month:.month,day:.day}"
- ParameterName: "JsonParsingEngine"
ParameterValue: "JQ-1.6"
DataFormatConversionConfiguration:
Enabled: true
InputFormatConfiguration:
Deserializer:
HiveJsonSerDe: {}
OutputFormatConfiguration:
Serializer:
ParquetSerDe: {}
SchemaConfiguration:
CatalogId: !Ref AWS::AccountId
RoleARN: !GetAtt FirehoseRole.Arn
DatabaseName: !Ref rawDataDB
TableName: !Ref rawDataTable
Region:
Fn::ImportValue: AWSRegion
VersionId: LATEST
FirehoseRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service: firehose.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: !Sub firehose-glue-${Envname}
PolicyDocument: |
{
"Version": "2012-10-17",
"Statement":
[
{
"Effect": "Allow",
"Action":
[
"glue:*",
"iam:ListRolePolicies",
"iam:GetRole",
"iam:GetRolePolicy",
"tag:GetResources",
"s3:*",
"cloudwatch:*",
"ssm:*"
],
"Resource": "*"
}
]
}