通常情况下,我喜欢正则表达式的挑战,更好的是解决它们。
但似乎我有一个我无法解决的案例。
我有一串由分号分隔的值,就像CSV行一样,它可能看起来像这样:
在此行中,我想匹配所有整数和整数范围,以便稍后提取它们。可能只有单个值(没有分号)。
经过大量搜索,我设法编写了以下表达式:
我正在使用的测试字符串:
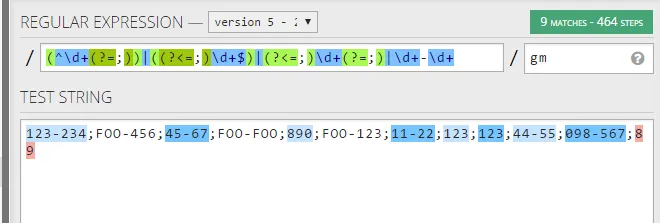
匹配数字和数字范围的正则表达式 你有什么想法,我漏掉了什么吗? 将“使用”此正则表达式的语言是C#,但我不知道这对我的问题是否有用。 由barlop添加 这是当前正则表达式给他的匹配项,如regex101.com链接所示
对于他的测试字符串
但似乎我有一个我无法解决的案例。
我有一串由分号分隔的值,就像CSV行一样,它可能看起来像这样:
123-234;FOO-456;45-67;FOO-FOO;890;FOO-123;11-22;123;123;44-55;098-567;890;123-FOO;在此行中,我想匹配所有整数和整数范围,以便稍后提取它们。可能只有单个值(没有分号)。
经过大量搜索,我设法编写了以下表达式:
(?:^|;)(?\d+-\d+)(?:$|;)|(?:^|;)(?\d+)(?:$|;)我正在使用的测试字符串:
123123-234;FOO-456;45-67;FOO-FOO;890;FOO-123;11-22;123;123;44-55;098-567;890;123-FOO;123-456123-FOOFOO-123FOO-FOO
第1行和第3行匹配正确,第4、5、6行匹配不正确。
在第2行中,只有两个值中的一个被正确匹配。
这里有一个链接到regex101.com的示例: https://regex101.com/r/zA7uI9/5
我还需要将整数和范围分别选择(在不同的组中)。
注意:我找到了一个问题,它可以帮助我,尝试了它的答案(通过调整),但它没有起作用。匹配数字和数字范围的正则表达式 你有什么想法,我漏掉了什么吗? 将“使用”此正则表达式的语言是C#,但我不知道这对我的问题是否有用。 由barlop添加 这是当前正则表达式给他的匹配项,如regex101.com链接所示
对于他的测试字符串
123-234;FOO-456;45-67;FOO-FOO;890;FOO-123;11-22;123;123;44-55;098-567;89
123-234
45-67
890
11-22
123
098-567
所以他的正则表达式似乎漏掉了其中一个123,还有44-45以及结尾处的89。
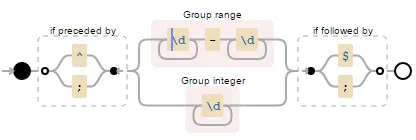
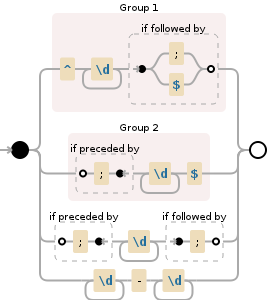
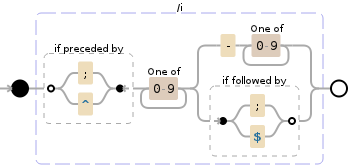
(?<=^|;)\d+(?:-\d+)?(?=$|;)。 - Wiktor Stribiżew(?<=^|;)(?:(?<float>\d+-\d+)|(?<int>\d+))(?=$|;)。 - Wiktor Stribiżew