我经常阅读有关如何进行强制推送的文章,其中提到所有未被拉取的远程仓库提交都将丢失。如果不需要特定的提交,也可以创建一个新分支,这在我看来更为常见,因为即使您现在不需要特定的代码或其他数据,也可能会在以后需要,我不认为有任何理由销毁它。
所以我的问题是,我有什么理由进行强制推送呢?
所以我的问题是,我有什么理由进行强制推送呢?
我经常看到有关如何强制推送的文章,以及没有拉取的远程仓库中的所有提交都会丢失
不完全正确:旧版本提交仍然在git reflog中引用。
即使您强制将代码推送到GitHub,您作为存储库所有者仍然可以查看被新历史覆盖的先前分支HEAD SHA1。请参见“GitHub是否记住提交ID?”。
否则您需要联系GitHub支持。
那么我的问题是,我强制推送的原因是什么?
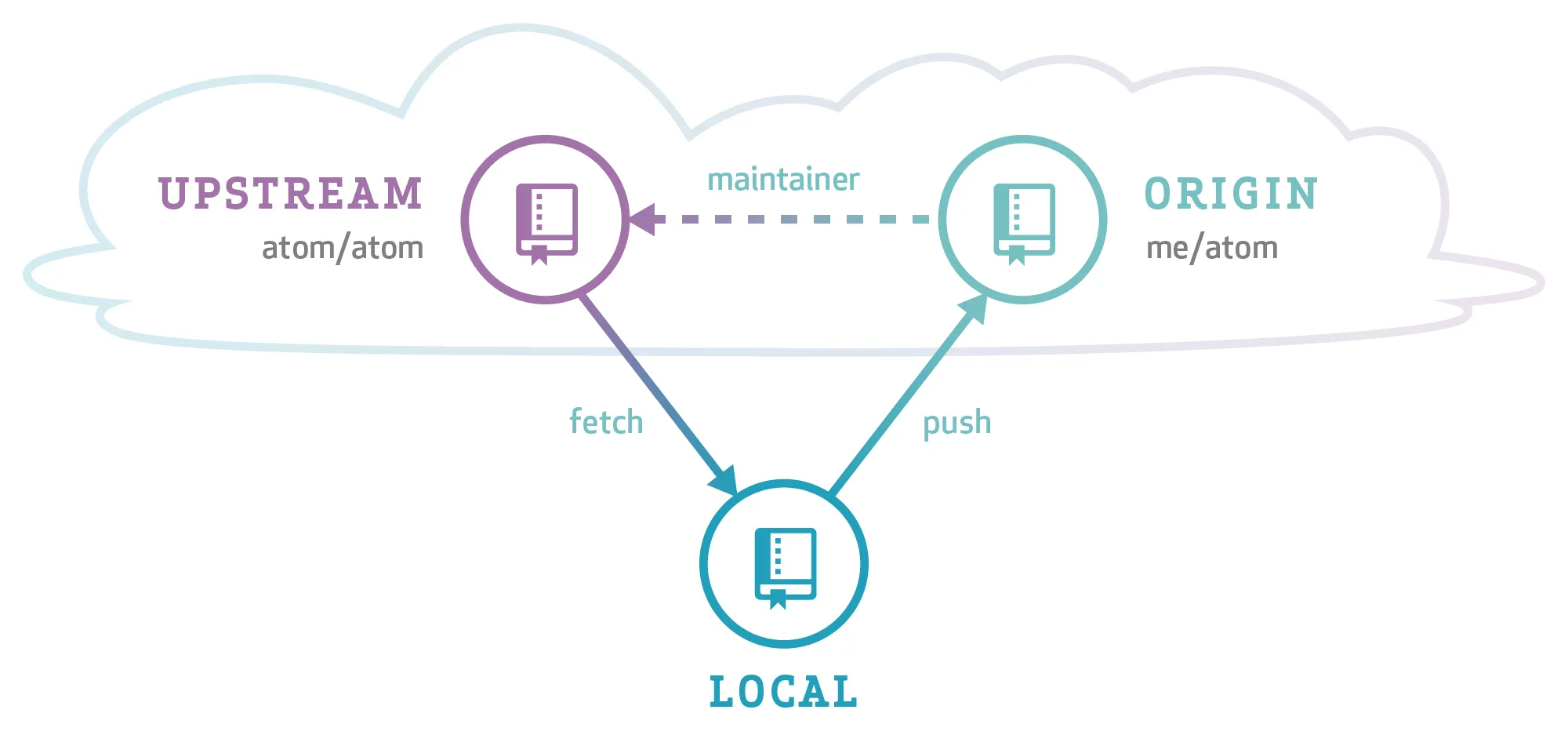
每当您是在一个分支上独自工作时(或者在fork的情况下是在一个仓库中),您可以强制推送。
这在拉取请求的情况下很常见,其中Web GUI足够智能以更新自身以考虑新的历史记录:您可以在将其重新设置为upstream/master之上的自己的分支上进行强制推送(假设您是唯一在该分支上工作的人)。
这是三角形工作流程的一部分。
OP bpoiss在评论中提到:
VonC在他的回答中提到,即使强制推送后数据仍然存在,因此您无法删除敏感信息,或者我错过了什么?
要在远程存储库上删除敏感信息,您需要在远程服务器端执行一些命令:
$ git reflog expire --expire=now --all
$ git gc --prune=now
(来源:删除敏感数据)
这意味着,当将敏感数据推送到GitHub时,您需要联系GitHub支持。
git rebase <branch>或git rebase -i HEAD~12来变基分支时,您将无法在没有它的情况下保存变基的工作。git filter-branch修改大量历史记录区段,或者可能通过BFG Repo Cleaner等工具进行修改。在任何其他情况下强制推送都可能非常危险。由于Git假定您知道自己在做什么,所以您有可能丢失历史记录。
最常见的情况是当您将敏感数据推送到远程仓库时。但是,如果在您强制推送之前有其他人拉取了代码,他仍然可以访问您的私人数据。