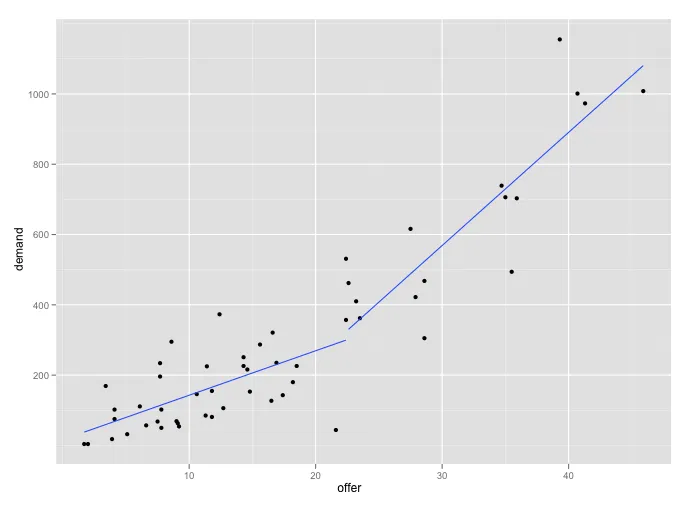
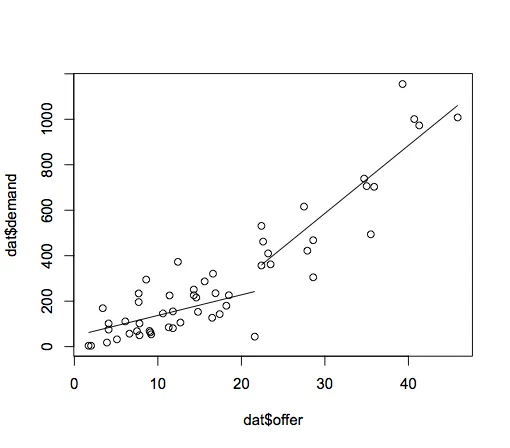
我有54个点。它们代表产品的供需情况。我想要展示在供应方面存在一个突破点。
首先,我对x轴(供应)进行排序并删除出现两次的值。我有47个值,但我删除了第一个和最后一个(考虑它们作为突破点没有意义)。突破长度为45:
Break<-(sort(unique(offer))[2:46])
然后,对于这些可能的断点,我估计一个模型,并将“d”中的残差标准误差(模型摘要对象中的第六个元素)保留下来。
d<-numeric(45)
for (i in 1:45) {
model<-lm(demand~(offer<Break[i])*offer + (offer>=Break[i])*offer)
d[i]<-summary(model)[[6]] }
绘制d后,我注意到我的较小残差标准误差是34,对应于"Break[34]": 22.4。因此我用我的最终断点编写了模型:
model<-lm(demand~(offer<22.4)*offer + (offer>=22.4)*offer)
最后,我对我的新模型感到满意。它比简单的线性模型显着优秀。现在我想画出来:
plot(demand~offer)
i <- order(offer)
lines(offer[i], predict(model,list(offer))[i])
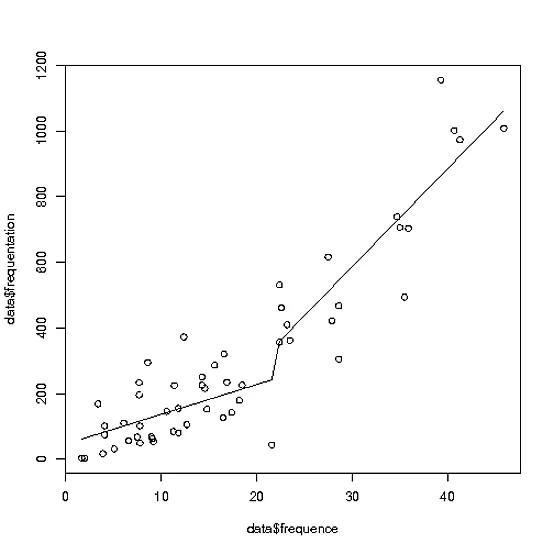
但是我收到一个警告信息:
Warning message:
In predict.lm(model, list(offer)) :
prediction from a rank-deficient fit may be misleading
而且更重要的是,我的图中的线条非常奇怪。
这是我的数据:
demand <- c(1155, 362, 357, 111, 703, 494, 410, 63, 616, 468, 973, 235,
180, 69, 305, 106, 155, 422, 44, 1008, 225, 321, 1001, 531, 143,
251, 216, 57, 146, 226, 169, 32, 75, 102, 4, 68, 102, 462, 295,
196, 50, 739, 287, 226, 706, 127, 85, 234, 153, 4, 373, 54, 81,
18)
offer <- c(39.3, 23.5, 22.4, 6.1, 35.9, 35.5, 23.2, 9.1, 27.5, 28.6, 41.3,
16.9, 18.2, 9, 28.6, 12.7, 11.8, 27.9, 21.6, 45.9, 11.4, 16.6,
40.7, 22.4, 17.4, 14.3, 14.6, 6.6, 10.6, 14.3, 3.4, 5.1, 4.1,
4.1, 1.7, 7.5, 7.8, 22.6, 8.6, 7.7, 7.8, 34.7, 15.6, 18.5, 35,
16.5, 11.3, 7.7, 14.8, 2, 12.4, 9.2, 11.8, 3.9)