我已经在Transformers中实现了MultiAttention头部。有很多实现方式让人感到困惑。有人能验证我的实现是否正确吗?
DotProductAttention 参考自:https://www.tensorflow.org/tutorials/text/transformer#setup
DotProductAttention 参考自:https://www.tensorflow.org/tutorials/text/transformer#setup
import tensorflow as tf
def scaled_dot_product(q,k,v):
#calculates Q . K(transpose)
qkt = tf.matmul(q,k,transpose_b=True)
#caculates scaling factor
dk = tf.math.sqrt(tf.cast(q.shape[-1],dtype=tf.float32))
scaled_qkt = qkt/dk
softmax = tf.nn.softmax(scaled_qkt,axis=-1)
z = tf.matmul(softmax,v)
#shape: (m,Tx,depth), same shape as q,k,v
return z
class MultiAttention(tf.keras.layers.Layer):
def __init__(self,d_model,num_of_heads):
super(MultiAttention,self).__init__()
self.d_model = d_model
self.num_of_heads = num_of_heads
self.depth = d_model//num_of_heads
self.wq = [tf.keras.layers.Dense(self.depth) for i in range(num_of_heads)]
self.wk = [tf.keras.layers.Dense(self.depth) for i in range(num_of_heads)]
self.wv = [tf.keras.layers.Dense(self.depth) for i in range(num_of_heads)]
self.wo = tf.keras.layers.Dense(d_model)
def call(self,x):
multi_attn = []
for i in range(self.num_of_heads):
Q = self.wq[i](x)
K = self.wk[i](x)
V = self.wv[i](x)
multi_attn.append(scaled_dot_product(Q,K,V))
multi_head = tf.concat(multi_attn,axis=-1)
multi_head_attention = self.wo(multi_head)
return multi_head_attention
#Calling the attention
multi = MultiAttention(d_model=512,num_of_heads=8)
m = 5; sequence_length = 4; word_embedding_dim = 512
sample_ip = tf.constant(tf.random.normal(shape=(m,sequence_length,word_embedding_dim)))
attn =multi(sample_ip)
#shape of op (attn): (5,4,512)
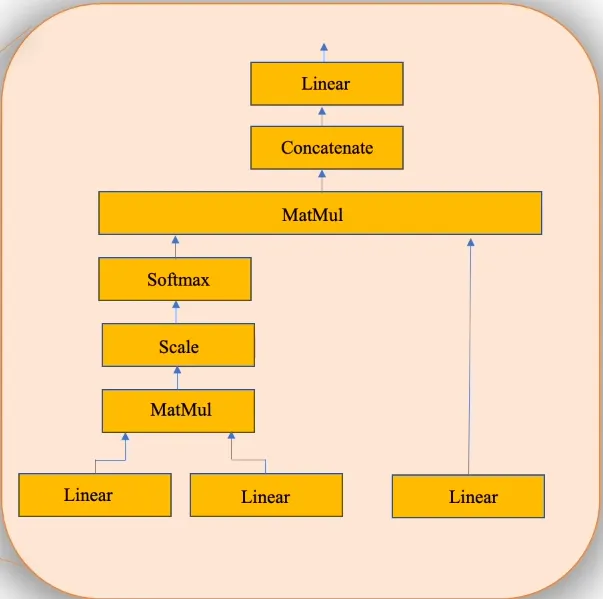 图片来源:https://www.youtube.com/watch?v=mMa2PmYJlCo
图片来源:https://www.youtube.com/watch?v=mMa2PmYJlCo
MultiAttention逻辑的审查。你已经在答案中解释了。谢谢。 - data_person