参考:Pandas DataFrame:从列中删除字符串中的不需要部分
参考上面链接中提供的答案。我研究了一些正则表达式,计划深入学习,但同时也需要帮助。
我的数据框如下:
df:
c_contofficeID
0 0109
1 0109
2 3434
3 123434
4 1255N9
5 0109
6 123434
7 55N9
8 5599
9 0109
伪代码
如果前两个字符是12,则删除它们。或者,对于前两个字符中没有12的情况,添加12。
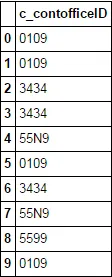
结果如下:
c_contofficeID
0 0109
1 0109
2 3434
3 3434
4 55N9
5 0109
6 3434
7 55N9
8 5599
9 0109
我将使用上面链接中的答案作为起点:
df['contofficeID'].replace(regex=True,inplace=True,to_replace=r'\D',value=r'')
I've tried the following:
Attempt 1)
df['contofficeID'].replace(regex=True,inplace=True,to_replace=r'[1][2]',value=r'')
尝试 2)
df['contofficeID'].replace(regex=True,inplace=True,to_replace=r'$[1][2]',value=r'')
尝试3)
df['contofficeID'].replace(regex=True,inplace=True,to_replace=r'?[1]?[2]',value=r'')