特殊小根堆是一种每个层级从左到右排序的小根堆。如何在最坏情况下以O(n)的时间复杂度按顺序打印所有n个元素?该小根堆由二叉堆实现,其中树是完全二叉树(见图)。以下是特殊小根堆的示例:
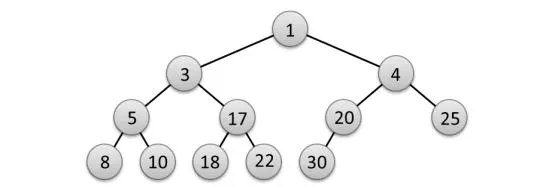
[1,3,4,5,8,10,17,18,20,22,25,30]
作业问题。
[1,3,4,5,8,10,17,18,20,22,25,30]
作业问题。n是一个独立于堆大小的参数,则在标准的基于比较模型下,这是不可能的。你需要额外的限制,比如更多预先存在的顺序,或者所有堆元素都是整数且在足够低的范围内。k的堆,根节点及其所有左孩子的链表值分别为1、2、3、...k。我们可以按任意顺序为这些节点的k-1个右孩子分配值>k,而不违反“特殊最小堆”条件,然后分配大于这些值的值来填充余下的堆。在此堆中打印前2k-1个值需要对可能按任意顺序排列的k-1个值进行排序,这不能在少于O(k*log(k))的时间内通过比较完成。n应该是堆的大小,则很简单。堆不变式是不必要的;它只关注层次结构是否排序。将第一层和第二层合并,然后将每个连续层次合并到已经合并的结果中的归并排序将花费O(n)的时间。第k个归并将2^k-1个已归并元素与下一层的<=2^k个元素合并,需要O(2^k)的时间。有O(log(n))个归并,将k从1到log(n)的O(2^k)相加得到O(n)。minHeap的定义要求它是一棵完全二叉树(就像示例中那样)。所以我仍然不确定。 - WhatsUp2^k个节点,因此该问题需要在O(2^k)时间内打印出所有节点。这仍然略有不同,与在O(k)时间内打印出前2k-1个值。 - WhatsUpn是一个与堆大小无关的参数。 - user2357112O(n)的复杂度,因为每个层级的大小形成了一个公比为2的等比数列。 - WhatsUp
O(nlogn)。 - Alaa M.O(n)个“指针”。决定前进哪一个将需要O(log n)次比较。由于你需要进行O(n)次操作,如果你能让运行时间低于O(n log n),那我会感到惊讶。 - Vincent van der Weele