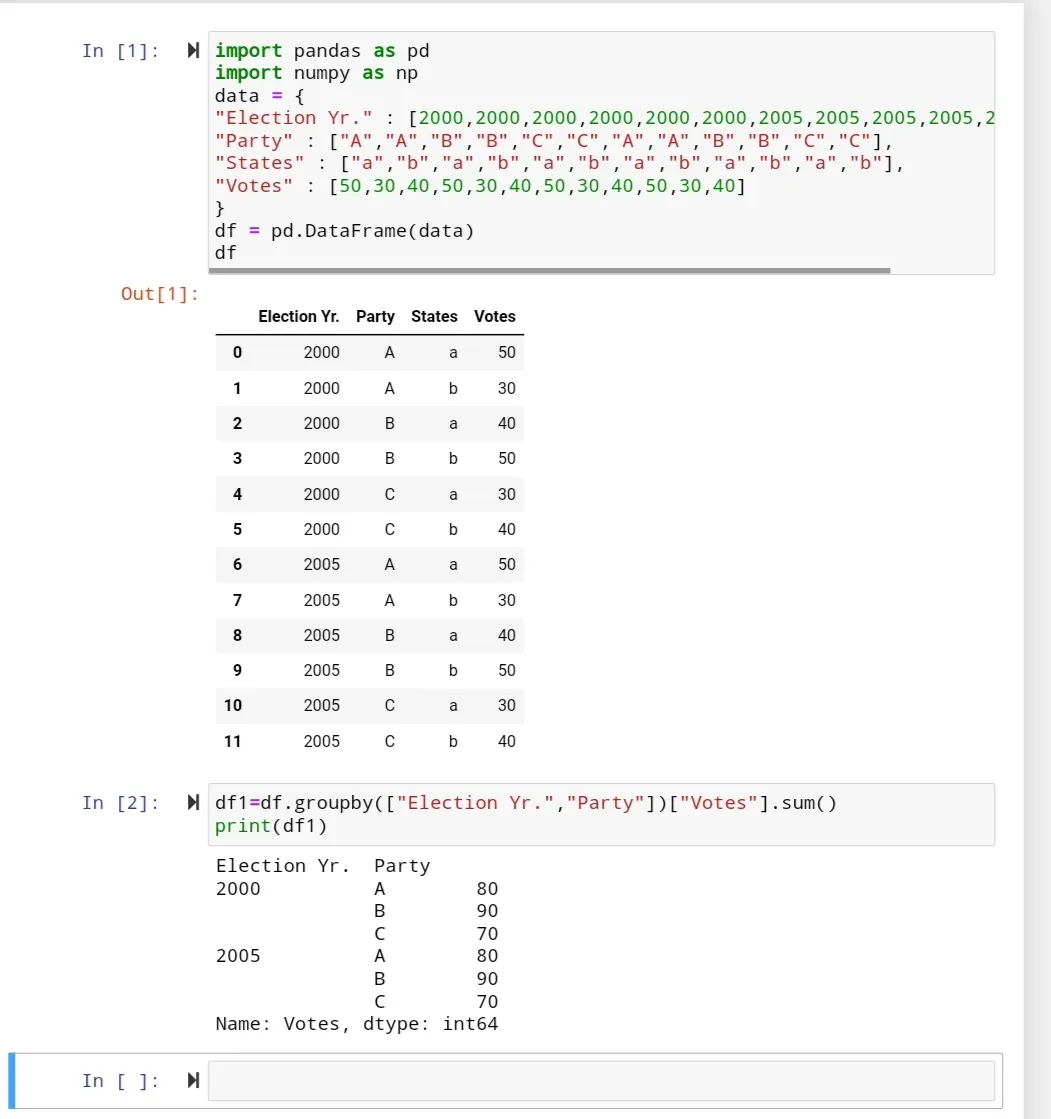
针对给定的数据框 df,其格式如下:
Election Yr. Party States Votes
0 2000 A a 50
1 2000 A b 30
2 2000 B a 40
3 2000 B b 50
4 2000 C a 30
5 2000 C b 40
6 2005 A a 50
7 2005 A b 30
8 2005 B a 40
9 2005 B b 50
10 2005 C a 30
11 2005 C b 40
我想获取对应年份中获得最高票数的政党。我已经使用以下代码按 "选举年份" 和 "政党" 进行分组,然后使用 .sum() 获取每个年份中每个政党的总票数。
df = df.groupby(['Election Yr.', 'Party']).sum()
如何每年获得最多选票的政党?我无法理解。
非常感谢您的支持。
{kind=link}