test = pd.DataFrame({'injury':['A', 'B', 'B', 'A', 'A', 'C', 'A', 'B', 'A'], 'crash_drinking':[1, 1, 1, 0, 0, 0, 1, 0, 1], 'crash_drugs':[0,0,0,1,1,0,0,1,1], 'driver_drinking':[1,1,0,0,0,0,0,1,0], 'driver_drugged':[0,0,0,0,1,0,0,1,0]})
crash_drinking crash_drugs driver_drinking driver_drugged injury
0 1 0 1 0 A
1 1 0 1 0 B
2 1 0 0 0 B
3 0 1 0 0 A
4 0 1 0 1 A
5 0 0 0 0 C
6 1 0 0 0 A
7 0 1 1 1 B
8 1 1 0 0 A
我希望我的输出结果看起来像这样(为了区别于上面的数据帧,列名已更改):
drinking crash drinking driver in crash drugged crash drugged driver in crash
A 2 1 2 1
B 2 1 1 0
对于第一行,"injury" = 'A',并且有以下筛选条件:
"酒驾事故"是指crash_drinking = 1且crash_drugs = 0的数量;
"酒驾司机事故"是指crash_drinking = 1、crash_drugs = 0、driver_drinking = 1以及driver_drugs = 0的情况;
"毒驾事故"是指crash_drinking = 0且crash_drugs = 1的情况;
"毒驾司机事故"是指crash_drinking = 0、crash_drugs = 1、driver_drinking = 0以及driver_drugs = 1的情况。
B行也是同样的情况,只是"injury" = 'B'。
目前我只设置了一堆.loc筛选器:
test.loc[(test['injury'] == 'A') & (test['crash_drinking'] == 1) & (test['crash_drugs'] == 0)]
test.loc[(test['injury'] == 'A') & (test['crash_drinking'] == 0) & (test['crash_drugs'] == 1)]
test.loc[(test['injury'] == 'A') & (test['crash_drinking'] == 1) & (test['crash_drugs'] == 0) & (test['driver_drinking'] == 1) & (test['driver_drugged'] == 0)]
等等。
我更愿意通过groupby或.apply()来完成这个任务,因为我认为这比循环所有这些查询要快。但我不确定正确的语法是什么。也许我应该在“injury”列上执行一个.groupby(),然后从那里开始......?
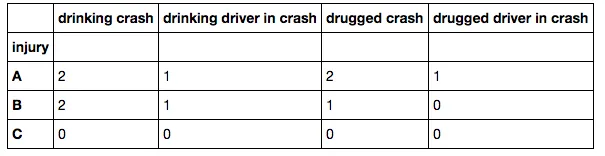
A['drinking crash']真的应该等于 4 吗?如果我正确地遵循逻辑,它应该等于 2。 - Dennis Golomazov