让我们创建 Julia 数据框架
df=convert(DataFrame, rand(10, 4))
它看起来像这样。我试图对这个数据框进行转置。如下图所示,Julia 数据框中的“transpose”函数似乎不起作用。
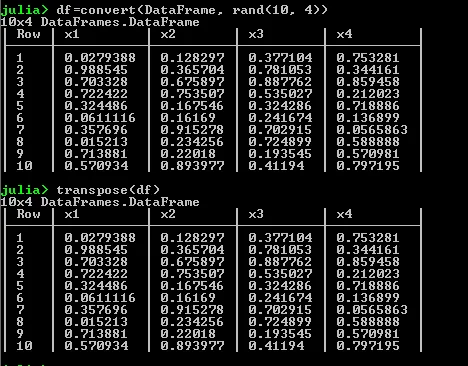
我在过去广泛地使用了 Python Pandas dataframe 包。 在 Python 中,只需使用“df.T”即可实现。 请告诉我一种转置此数据框的方法。
史蒂芬的答案存在问题,因为列的顺序没有被保留(如果您不相信,请尝试以下 DataFrame)。
julia> df = DataFrame(A = 1:4, B = 5:8, AA = 15:18)
4×3 DataFrame
│ Row │ A │ B │ AA │
│ │ Int64 │ Int64 │ Int64 │
├─────┼───────┼───────┼───────┤
│ 1 │ 1 │ 5 │ 15 │
│ 2 │ 2 │ 6 │ 16 │
│ 3 │ 3 │ 7 │ 17 │
│ 4 │ 4 │ 8 │ 18 │
但是可以使用以下方法对这个DataFrame进行转置(保持列/行的顺序):
但是可以使用以下方法对这个DataFrame进行转置(保持列/行的顺序):
julia> DataFrame([[names(df)]; collect.(eachrow(df))], [:column; Symbol.(axes(df, 1))])
3×5 DataFrame
│ Row │ column │ 1 │ 2 │ 3 │ 4 │
│ │ Symbol │ Int64 │ Int64 │ Int64 │ Int64 │
├─────┼────────┼───────┼───────┼───────┼───────┤
│ 1 │ A │ 1 │ 2 │ 3 │ 4 │
│ 2 │ B │ 5 │ 6 │ 7 │ 8 │
│ 3 │ AA │ 15 │ 16 │ 17 │ 18 │
参考资料: https://github.com/JuliaData/DataFrames.jl/issues/2065#issuecomment-568937464
julia> using DataFrames
julia> df = DataFrame(A = 1:4, B = 5:8)
4×2 DataFrame
│ Row │ A │ B │
│ │ Int64 │ Int64 │
├─────┼───────┼───────┤
│ 1 │ 1 │ 5 │
│ 2 │ 2 │ 6 │
│ 3 │ 3 │ 7 │
│ 4 │ 4 │ 8 │
julia> colnames = names(df)
2-element Array{Symbol,1}:
:A
:B
julia> df[!, :id] = 1:size(df, 1)
1:4
julia> df
4×3 DataFrame
│ Row │ A │ B │ id │
│ │ Int64 │ Int64 │ Int64 │
├─────┼───────┼───────┼───────┤
│ 1 │ 1 │ 5 │ 1 │
│ 2 │ 2 │ 6 │ 2 │
│ 3 │ 3 │ 7 │ 3 │
│ 4 │ 4 │ 8 │ 4 │
在DataFrame文档中建议添加:id列来帮助解压缩。
现在将要转置的列进行堆叠:
julia> dfl = stack(df, colnames)
8×3 DataFrame
│ Row │ variable │ value │ id │
│ │ Symbol │ Int64 │ Int64 │
├─────┼──────────┼───────┼───────┤
│ 1 │ A │ 1 │ 1 │
│ 2 │ A │ 2 │ 2 │
│ 3 │ A │ 3 │ 3 │
│ 4 │ A │ 4 │ 4 │
│ 5 │ B │ 5 │ 1 │
│ 6 │ B │ 6 │ 2 │
│ 7 │ B │ 7 │ 3 │
│ 8 │ B │ 8 │ 4 │
然后解除堆叠,交换id和变量名称(这就是为什么添加:id列是必要的原因)。
julia> dfnew = unstack(dfl, :variable, :id, :value)
2×5 DataFrame
│ Row │ variable │ 1 │ 2 │ 3 │ 4 │
│ │ Symbol │ Int64⍰ │ Int64⍰ │ Int64⍰ │ Int64⍰ │
├─────┼──────────┼────────┼────────┼────────┼────────┤
│ 1 │ A │ 1 │ 2 │ 3 │ 4 │
│ 2 │ B │ 5 │ 6 │ 7 │ 8 │
这适用于不太复杂的数据框。其中一个数据框的列用于生成列名。其他列的名称成为行名。
function all_unique(v::Vector)::Bool
return length(unique(v)) == length(v)
end
function df_add_first_column(
df::DataFrame,
colname::Union{Symbol,String},
col_data
)
df1 = DataFrame([colname => col_data])
hcat(df1, df)
end
function df_transpose(df::DataFrame, col::Union{Symbol, String})::DataFrame
@assert all_unique(df[!, col]) "Column `col` contains non-unique elements"
function foo(i)
string(df[i, col]) => collect(df[i, Not(col)])
end
dft = DataFrame(map(foo, 1:nrow(df)))
return df_add_first_column(dft, "Row", filter(x -> x != string(col), names(df)))
end
例子:
df0 = DataFrame(A = [1, 2, 3], B = rand(3), C = rand(3))
3×3 DataFrame
Row │ A B C
│ Int64 Float64 Float64
─────┼───────────────────────────
1 │ 1 0.578605 0.590092
2 │ 2 0.350394 0.399114
3 │ 3 0.90852 0.710629
2×4 DataFrame
Row │ Row 1 2 3
│ String Float64 Float64 Float64
─────┼──────────────────────────────────────
1 │ B 0.578605 0.350394 0.90852
2 │ C 0.590092 0.399114 0.710629
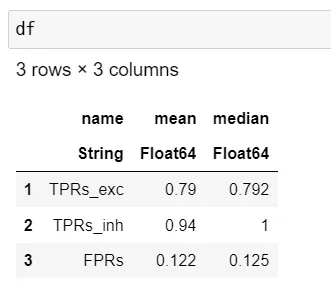
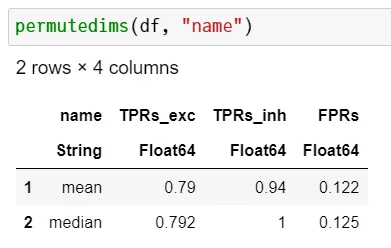
permutedims 可以做到这一点。
通常在你想转置一个数据框时,你已经有了一个带有名称的列(字符串或符号):
df = DataFrame(rand(10, 4), :auto)
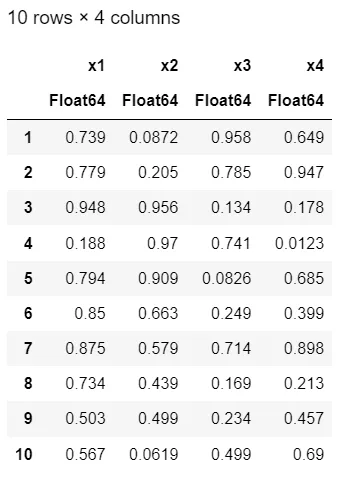
...新列没有名称。因此,我们将使用行号:
df.id = string.(1:nrow(df)) # Add column with names
permutedims(df, "id", "")
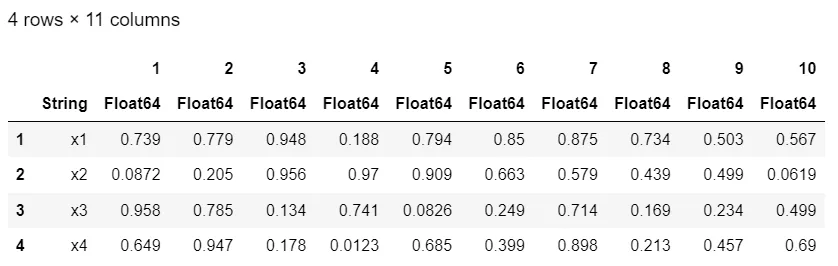 我们使用了
我们使用了permutedims的可选第三个参数,将新的id列重命名为空字符串,这并非必需,但可以很好看。
M'即可完成操作。如果该矩阵嵌入在DataFrame中,则需要将其转换为矩阵进行转置,然后(如果必要)再将其转回DataFrame。在这种情况下,可以使用DataFrame(Matrix(df)')来完成操作。 - Dan Getz'表示共轭转置,而正常的转置是.'。在实践中,共轭转置更为常见,这就是为什么选择这种语法的原因。 - Fengyang Wang