我希望将多个列的多个函数应用于一个groupby对象,从而得到一个新的pandas.DataFrame。
我知道如何分步骤完成:
by_user = lasts.groupby('user')
elapsed_days = by_user.apply(lambda x: (x.elapsed_time * x.num_cores).sum() / 86400)
running_days = by_user.apply(lambda x: (x.running_time * x.num_cores).sum() / 86400)
user_df = elapsed_days.to_frame('elapsed_days').join(running_days.to_frame('running_days'))
这导致user_df的结果为: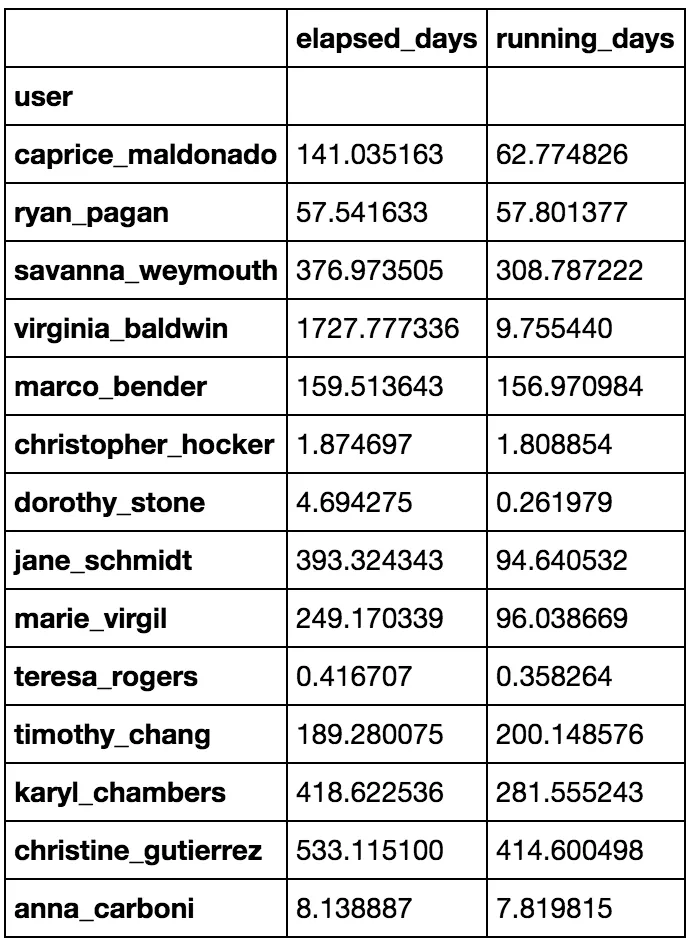
然而,我怀疑还有更好的方法,类似于:
by_user.agg({'elapsed_days': lambda x: (x.elapsed_time * x.num_cores).sum() / 86400,
'running_days': lambda x: (x.running_time * x.num_cores).sum() / 86400})
然而,这不起作用,因为据我所知 agg() 是针对 pandas.Series 进行操作的。
我找到了这个问题和答案,但解决方案对我来说看起来相当丑陋,考虑到答案已经将近四年了,现在可能有更好的方法。