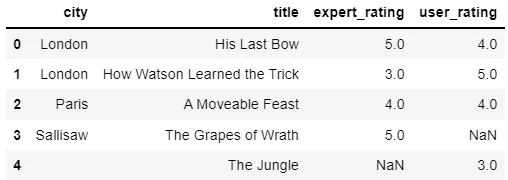
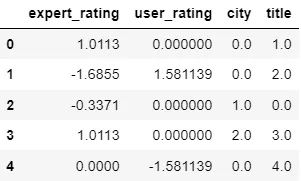
我希望将输出的np数组与特征匹配以创建一个新的Pandas数据帧。
这是我的流程管道:
这是我的流程管道:
from sklearn.pipeline import Pipeline
# Categorical pipeline
categorical_preprocessing = Pipeline(
[
('Imputation', SimpleImputer(missing_values=np.nan, strategy='most_frequent')),
('Ordinal encoding', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=-1)),
]
)
# Continuous pipeline
continuous_preprocessing = Pipeline(
[
('Imputation', SimpleImputer(missing_values=np.nan, strategy='mean')),
('Scaling', StandardScaler())
]
)
# Creating preprocessing pipeline
preprocessing = make_column_transformer(
(continuous_preprocessing, continuous_cols),
(categorical_preprocessing, categorical_cols),
)
# Final pipeline
pipeline = Pipeline(
[('Preprocessing', preprocessing)]
)
这是我的命名方式:
X_train = pipeline.fit_transform(X_train)
X_val = pipeline.transform(X_val)
X_test = pipeline.transform(X_test)
我获取特征名称时得到的结果如下:
pipeline['Preprocessing'].transformers_[1][1]['Ordinal encoding'].get_feature_names()
输出:
AttributeError: 'OrdinalEncoder' object has no attribute 'get_feature_names'
这里有一个类似的stackoverflow问题:Sklearn Pipeline: Get feature names after OneHotEncode In ColumnTransformer
sklearn版本是多少? - user17242583