统计出现次数的其他可能方法包括使用 (i) collections 模块中的 Counter,(ii) numpy 库中的 unique 和 (iii) pandas 中的 groupby + size。
使用 collections.Counter:
from collections import Counter
out = pd.Series(Counter(df['word']))
使用
numpy.unique:
import numpy as np
i, c = np.unique(df['word'], return_counts = True)
out = pd.Series(c, index = i)
使用
groupby +
size:
out = pd.Series(df.index, index=df['word']).groupby(level=0).size()
value_counts有一个非常好的特性,它可以对计数进行排序。如果需要对计数进行排序,则
value_counts是最简单和性能最好的方法(即使在处理非常大的Series时,它仍然略逊于其他方法)。
基准测试
(如果不重要则无需对计数进行排序):
如果我们查看运行时间,则取决于存储在DataFrame列/ Series中的数据。
如果Series的dtype为object,则非常大的Series的最快方法是使用collections.Counter,但通常value_counts也非常有竞争力。
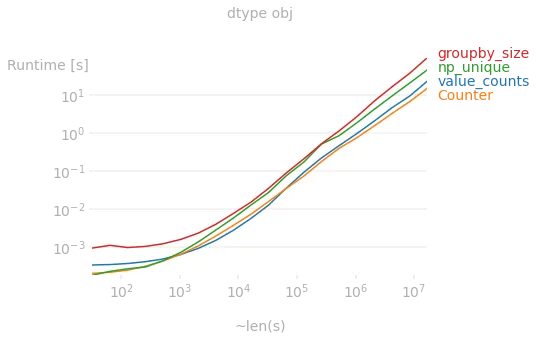
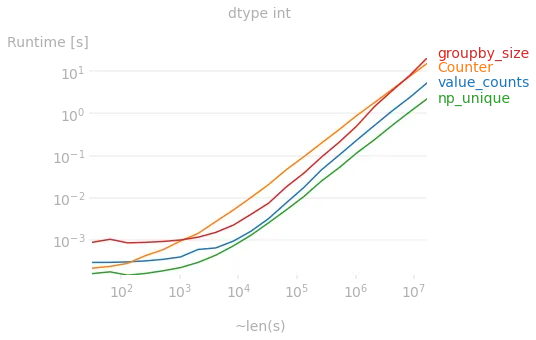
但是,如果dtype为int,则最快的方法是使用numpy.unique:
生成图表所使用的代码:
import perfplot
import numpy as np
import pandas as pd
from collections import Counter
def creator(n, dt='obj'):
s = pd.Series(np.random.randint(2*n, size=n))
return s.astype(str) if dt=='obj' else s
def plot_perfplot(datatype):
perfplot.show(
setup = lambda n: creator(n, datatype),
kernels = [lambda s: s.value_counts(),
lambda s: pd.Series(Counter(s)),
lambda s: pd.Series((ic := np.unique(s, return_counts=True))[1], index = ic[0]),
lambda s: pd.Series(s.index, index=s).groupby(level=0).size()
],
labels = ['value_counts', 'Counter', 'np_unique', 'groupby_size'],
n_range = [2 ** k for k in range(5, 25)],
equality_check = lambda *x: (d:= pd.concat(x, axis=1)).eq(d[0], axis=0).all().all(),
xlabel = '~len(s)',
title = f'dtype {datatype}'
)
plot_perfplot('obj')
plot_perfplot('int')
df.word.value_counts()['myword']的速度大约是len(df[df.word == 'myword'])的两倍。 - fantabolous.get()方法。在这种情况下,.get()将返回None,而使用括号方法将引发错误。 - elPastordf['word'].value_counts().nlargest(10)。 - cristiandatum