在我的使用案例中,我想要按命名空间聚合内存/CPU的使用情况,因为我想要看到在我的小型K3s集群中运行的Harbor系统是多么“重”或“轻”,所以我使用
kubernetes Python客户端编写了这个Python脚本:
from kubernetes import client, config
import matplotlib.pyplot as plt
import pandas as pd
def cpu_n(cpu_str: str):
if cpu_str == "0":
return 0.0
assert cpu_str.endswith("n")
return float(cpu_str[:-1])
def mem_Mi(mem_str: str):
if mem_str == "0":
return 0.0
assert mem_str.endswith("Ki") or mem_str.endswith("Mi")
val = float(mem_str[:-2])
if mem_str.endswith("Ki"):
return val / 1024.0
if mem_str.endswith("Mi"):
return val
config.load_kube_config()
api = client.CustomObjectsApi()
v1 = client.CoreV1Api()
cpu_usage_pct = {}
mem_usage_mb = {}
namespaces = [item.metadata.name for item in v1.list_namespace().items]
for ns in namespaces:
resource = api.list_namespaced_custom_object(group="metrics.k8s.io", version="v1beta1", namespace=ns, plural="pods")
cpu_total_n = 0.0
mem_total_Mi = 0.0
for pod in resource["items"]:
for container in pod["containers"]:
usage = container["usage"]
cpu_total_n += cpu_n(usage["cpu"])
mem_total_Mi += mem_Mi(usage["memory"])
if mem_total_Mi > 0:
mem_usage_mb[ns] = mem_total_Mi
if cpu_total_n > 0:
cpu_usage_pct[ns] = cpu_total_n * 100 / 10**9
df_mem = pd.DataFrame({"ns": mem_usage_mb.keys(), "memory_mbi": mem_usage_mb.values()})
df_mem.sort_values("memory_mbi", inplace=True)
_, [ax1, ax2] = plt.subplots(2, 1, figsize=(12, 12))
ax1.barh("ns", "memory_mbi", data=df_mem)
ax1.set_ylabel("Namespace", size=14)
ax1.set_xlabel("Memory Usage [MBi]", size=14)
total_memory_used_Mi = round(sum(mem_usage_mb.values()))
ax1.set_title(f"Memory usage by namespace [{total_memory_used_Mi}Mi total]", size=16)
df_cpu = pd.DataFrame({"ns": cpu_usage_pct.keys(), "cpu_pct": cpu_usage_pct.values()})
df_cpu.sort_values("cpu_pct", inplace=True)
ax2.barh("ns", "cpu_pct", data=df_cpu)
ax2.set_ylabel("Namespace", size=14)
ax2.set_xlabel("CPU Usage [%]", size=14)
total_cpu_usage_pct = round(sum(cpu_usage_pct.values()))
ax2.set_title(f"CPU usage by namespace [{total_cpu_usage_pct}% total]", size=16)
plt.show()
示例输出如下:
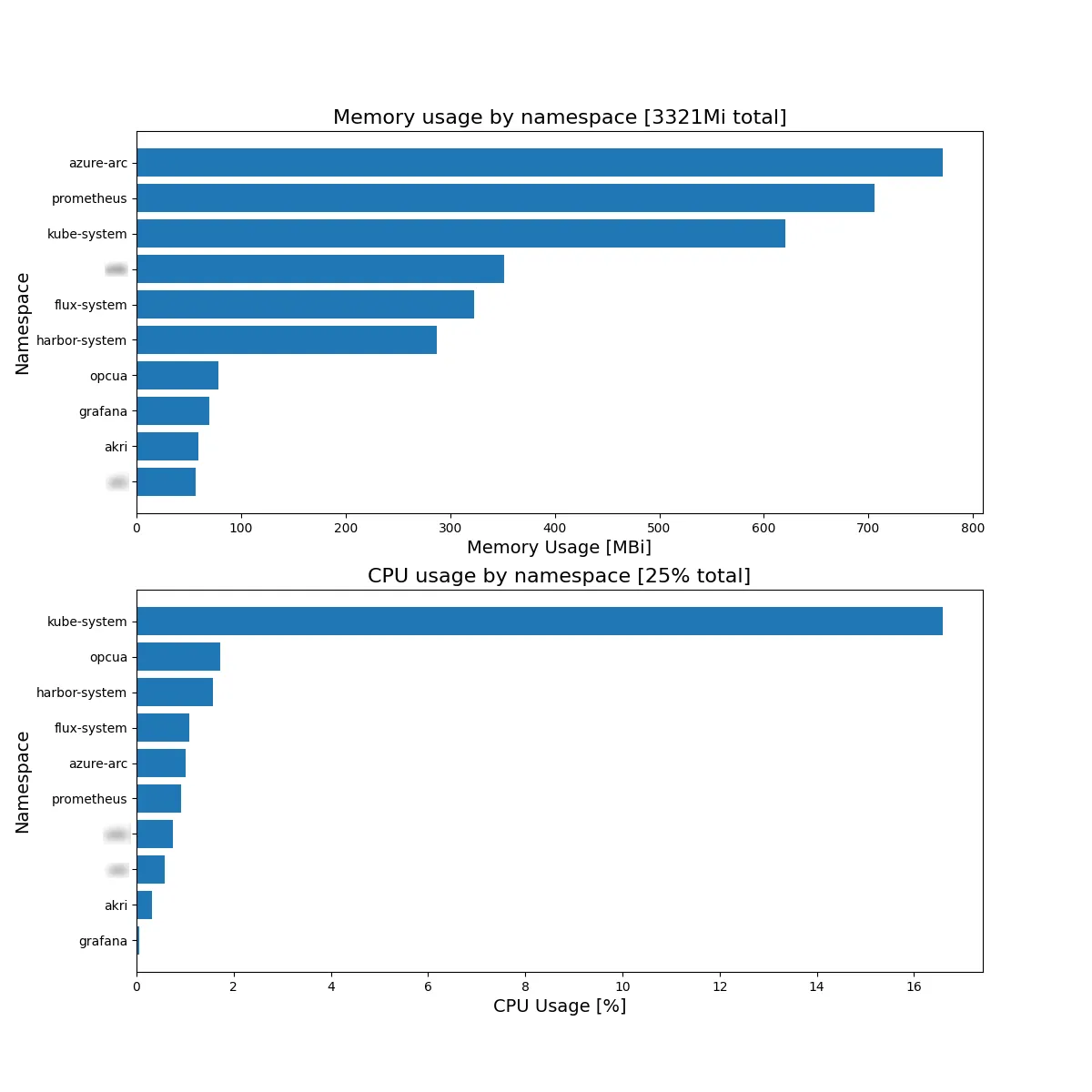
当然,请记住这只是系统内存和CPU使用情况的快照,随着工作负载的活跃程度的增加或减少,它可能会有很大变化。