Kubernetes如何计算HPA的CPU利用率?
7
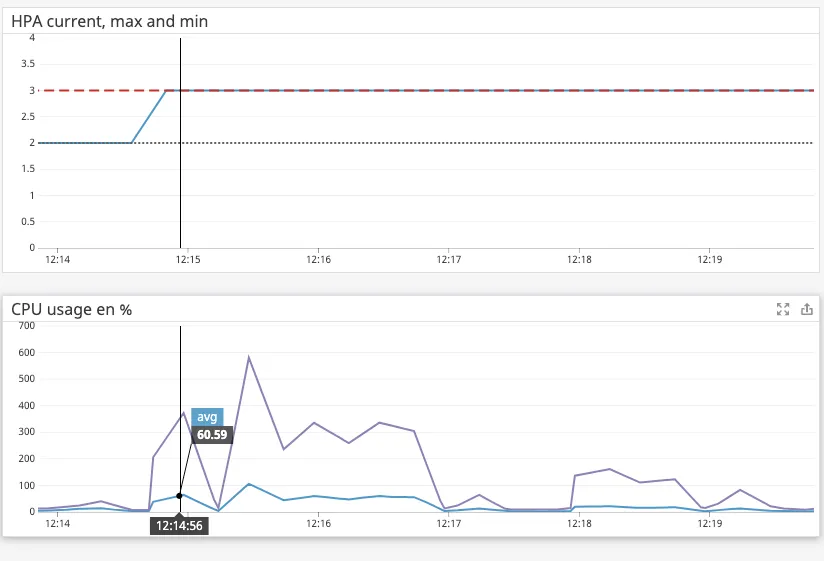
- Mouna
2
你使用的是哪个版本的Kubernetes?(在此之前我只看过Knative中的HPA https://ahmet.im/blog/knative-better-kubernetes-networking/, https://knative.dev/v0.12-docs/serving/configuring-autoscaling/) - VonC
你能展示一下你正在自动扩展的部署定义吗? - Ottovsky
2个回答
5
请注意,我手头没有Kubernetes集群,这是基于k8s源代码的理论答案。
看看这是否符合您的经验。
Kubernetes是开源的,这里似乎是HPA代码。(链接) 函数
看看这是否符合您的经验。
Kubernetes是开源的,这里似乎是HPA代码。(链接) 函数
GetResourceReplica和calcPlainMetricReplicas(用于非利用率百分比)根据当前度量计算副本数量。
两者都使用由GetMetricUtilizationRatio返回的usageRatio,将此值乘以Replica中当前就绪Pod的数量,以获得新的Pod数:New_number_of_pods = Old_numbers_of_ready_pods * usageRatio
这里有一个容差检查(即如果usageRatio足够接近1,就什么也不做),而待处理和未知状态的Pod将被忽略(认为使用0%的资源),而没有指标的Pod则被认为使用100%的资源。
usageRatio由GetResourceUtilizationRatio计算,该函数传入所有Pod的指标和请求资源,其计算如下:
utilization = Total_sum_resource_usage_all_pods / Total_sum_resource_requests_all_pods
usageRatio = utilization * 100 / targetUtilization
targetUtilization 来自 HPA 规范。
在这种情况下,代码比我的摘要更易于阅读。在此上下文中,“request”一词是指“资源请求”(这是一个有根据的猜测)。
因此,我会说,90% 的资源使用率跨越所有 pod 计算,就像它们都是单个 pod 请求每个 pod 的总和,并收集指标,就像它们都在单个专用节点上运行一样。
- Margaret Bloom
0
根据 https://github.com/kubernetes/kubernetes/issues/78988#issuecomment-502106361 的说法,这取决于配置且是指度量服务器和 kublet 报告的问题,HPA 应该只使用信息:https://kubernetes.io/docs/tasks/debug-application-cluster/resource-metrics-pipeline/#cpu
我认为持续时间应由 kubelet 的 --housekeeping-interval 定义,并默认为 10 秒钟。
- till
1
我可能也是错的,它可能是在 https://github.com/kubernetes/kubernetes/blob/master/staging/src/k8s.io/kubelet/config/v1beta1/types.go 中定义的某个持续时间。 - till
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接