我正在使用这个 GSDMM Python 实现来聚类一组文本消息的数据集。根据原始论文,GSDMM 收敛很快(大约 5 次迭代)。我也已经收敛到了一定数量的聚类,但在每次迭代中仍然有很多消息被转移,因此很多消息仍在更改它们所属的聚类。
我的输出结果看起来像:
In stage 0: transferred 9511 clusters with 150 clusters populated
In stage 1: transferred 4974 clusters with 138 clusters populated
In stage 2: transferred 2533 clusters with 90 clusters populated
….
In stage 34: transferred 1403 clusters with 47 clusters populated
In stage 35: transferred 1410 clusters with 47 clusters populated
In stage 36: transferred 1430 clusters with 48 clusters populated
In stage 37: transferred 1463 clusters with 48 clusters populated
In stage 38: transferred 1359 clusters with 48 clusters populated
在最初的论文中,图3显示了相同的模式,聚类数量几乎保持不变。
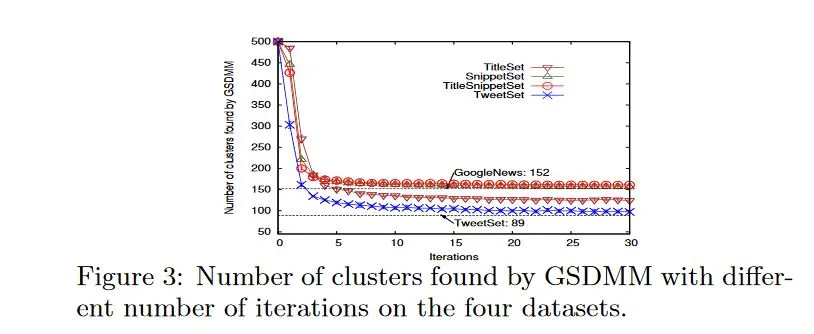
我无法确定他们的数据集中有多少消息仍在传输。我的理解是,这个数字应该尽可能小,在最好的情况下为零(因此每个消息都“找到”了正确的聚类)。因此,聚类数量可能会收敛,但这并不能说明算法/聚类的质量。我的理解是否正确?
还有可能是我的数据不足以获得适当的聚类。
K=600开始,收敛到N=47-48群集。我认为它不需要收敛到一个特定的数字,可能只是有一些消息适合于几个群集。您还可以在“TweetSet”图中看到这种行为,它会稍微移动一下。 经过长时间运行的网格搜索后,我的超参数为:alpha=0.01,beta=0.05。对于 K,我认为重要的是它足够大。 - simonmgp.score,您可以查看算法在将输入文本分配给聚类时的确定程度。我使用算法对所有输入文档的确定程度的平均值来比较不同的超参数。这是我自己想出来的一种度量标准,因为我和你一样也遇到了相同的困难 :) 我还在此帖子中讨论了类似的问题。 - simon