我有一个pandas数据框,格式如下:
df:
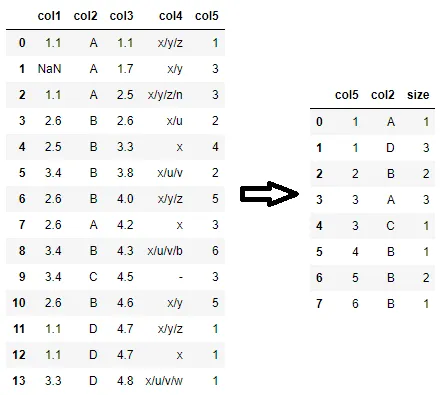
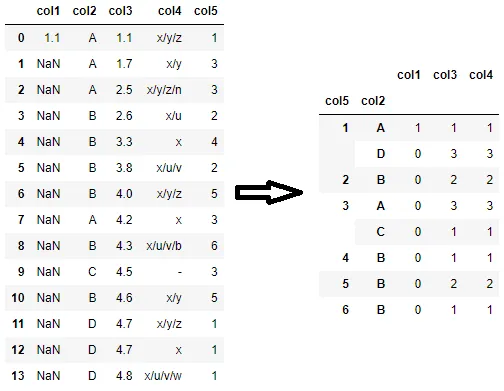
我想按照每一行来计算数量,如下所示。期望的输出:
如何获得我期望的输出?我想找到每个 'col2' 值的最大计数。
df = pd.DataFrame([
[1.1, 1.1, 1.1, 2.6, 2.5, 3.4,2.6,2.6,3.4,3.4,2.6,1.1,1.1,3.3],
list('AAABBBBABCBDDD'),
[1.1, 1.7, 2.5, 2.6, 3.3, 3.8,4.0,4.2,4.3,4.5,4.6,4.7,4.7,4.8],
['x/y/z','x/y','x/y/z/n','x/u','x','x/u/v','x/y/z','x','x/u/v/b','-','x/y','x/y/z','x','x/u/v/w'],
['1','3','3','2','4','2','5','3','6','3','5','1','1','1']
]).T
df.columns = ['col1','col2','col3','col4','col5']
df:
col1 col2 col3 col4 col5
0 1.1 A 1.1 x/y/z 1
1 1.1 A 1.7 x/y 3
2 1.1 A 2.5 x/y/z/n 3
3 2.6 B 2.6 x/u 2
4 2.5 B 3.3 x 4
5 3.4 B 3.8 x/u/v 2
6 2.6 B 4 x/y/z 5
7 2.6 A 4.2 x 3
8 3.4 B 4.3 x/u/v/b 6
9 3.4 C 4.5 - 3
10 2.6 B 4.6 x/y 5
11 1.1 D 4.7 x/y/z 1
12 1.1 D 4.7 x 1
13 3.3 D 4.8 x/u/v/w 1
我想按照每一行来计算数量,如下所示。期望的输出:
col5 col2 count
1 A 1
D 3
2 B 2
etc...
如何获得我期望的输出?我想找到每个 'col2' 值的最大计数。