一种方法是获取给定输入的SeqSelfAttention的输出,并将它们组织起来以显示每个通道的预测结果(见下文)。对于更高级的内容,请查看iNNvestigate库(包括使用示例)。
更新:我还可以推荐我编写的See RNN软件包。
说明:
show_features_1D获取
layer_name(可以是子字符串)层的输出并显示每个通道的预测结果(已标记),其中时间步长沿x轴,输出值沿y轴。
input_data=数据的单个批次,形状为(1, input_shape)prefetched_outputs = 已经获取的层输出;覆盖input_datamax_timesteps = 最多要显示的时间步数max_col_subplots = 水平方向上最多要显示的子图数equate_axes = 强制所有x-和y-轴相等(建议用于公平比较)show_y_zero = 是否显示y=0为红线channel_axis = 层特征维数(例如LSTM的units,即最后一个维度)scale_width, scale_height = 缩放显示图像宽度和高度dpi = 图像质量(每英寸点数)
可视化说明(下面):
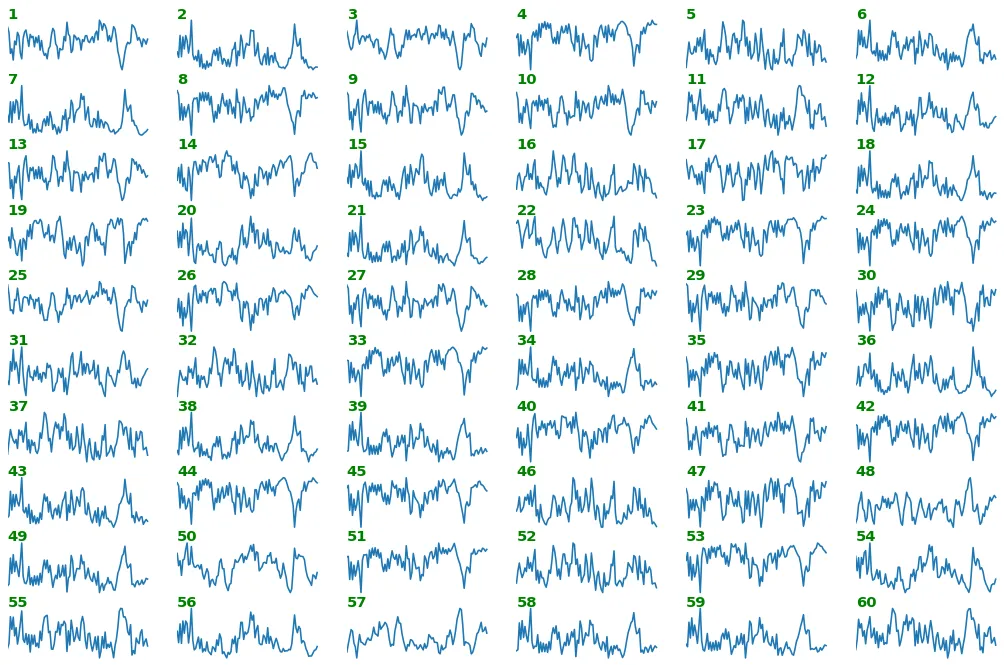
- 首先有用的是查看提取特征的形状,无论其大小 - 提供有关例如频率内容的信息
- 第二个对于查看特征关系很有用——例如相对大小、偏差和频率。下面的结果与其上方的图像形成鲜明对比,因为运行
print(outs_1)可以发现所有幅度都非常小,并且变化不大,因此包括y=0点并使轴相等会产生类似于线的视觉效果,这可以解释为自注意力具有偏向性。
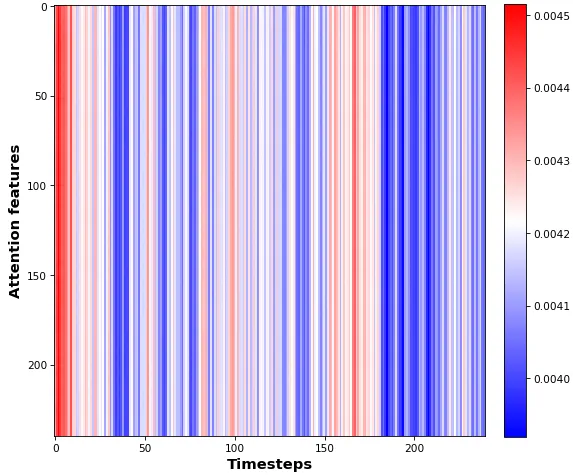
- 第三个适用于可视化太多以至于不能像以上那样可视化的特征;使用
batch_shape定义模型而不是input_shape可以去除打印形状中的所有?,我们可以看到第一个输出的形状为(10, 60, 240),第二个输出的形状为(10, 240, 240)。换句话说,第一个输出返回LSTM通道注意力,第二个输出返回“时间步长注意力”。下面的热图结果可以解释为显示有关时间步长的注意力“降温”。
SeqWeightedAttention更容易进行可视化,但可视化内容不是很多;您需要除去上方的Flatten才能使其正常工作。然后,注意力的输出形状变为(10, 60)和(10, 240)——对于这两个形状,您可以使用简
from keras.layers import Input, Dense, LSTM, Flatten, concatenate
from keras.models import Model
from keras.optimizers import Adam
from keras_self_attention import SeqSelfAttention
import numpy as np
ipt = Input(shape=(240,4))
x = LSTM(60, activation='tanh', return_sequences=True)(ipt)
x = SeqSelfAttention(return_attention=True)(x)
x = concatenate(x)
x = Flatten()(x)
out = Dense(1, activation='sigmoid')(x)
model = Model(ipt,out)
model.compile(Adam(lr=1e-2), loss='binary_crossentropy')
X = np.random.rand(10,240,4)
Y = np.random.randint(0,2,(10,1))
model.train_on_batch(X, Y)
outs = get_layer_outputs(model, 'seq', X[0:1], 1)
outs_1 = outs[0]
outs_2 = outs[1]
show_features_1D(model,'lstm',X[0:1],max_timesteps=100,equate_axes=False,show_y_zero=False)
show_features_1D(model,'lstm',X[0:1],max_timesteps=100,equate_axes=True, show_y_zero=True)
show_features_2D(outs_2[0])

def show_features_1D(model=None, layer_name=None, input_data=None,
prefetched_outputs=None, max_timesteps=100,
max_col_subplots=10, equate_axes=False,
show_y_zero=True, channel_axis=-1,
scale_width=1, scale_height=1, dpi=76):
if prefetched_outputs is None:
layer_outputs = get_layer_outputs(model, layer_name, input_data, 1)[0]
else:
layer_outputs = prefetched_outputs
n_features = layer_outputs.shape[channel_axis]
for _int in range(1, max_col_subplots+1):
if (n_features/_int).is_integer():
n_cols = int(n_features/_int)
n_rows = int(n_features/n_cols)
fig, axes = plt.subplots(n_rows,n_cols,sharey=equate_axes,dpi=dpi)
fig.set_size_inches(24*scale_width,16*scale_height)
subplot_idx = 0
for row_idx in range(axes.shape[0]):
for col_idx in range(axes.shape[1]):
subplot_idx += 1
feature_output = layer_outputs[:,subplot_idx-1]
feature_output = feature_output[:max_timesteps]
ax = axes[row_idx,col_idx]
if show_y_zero:
ax.axhline(0,color='red')
ax.plot(feature_output)
ax.axis(xmin=0,xmax=len(feature_output))
ax.axis('off')
ax.annotate(str(subplot_idx),xy=(0,.99),xycoords='axes fraction',
weight='bold',fontsize=14,color='g')
if equate_axes:
y_new = []
for row_axis in axes:
y_new += [np.max(np.abs([col_axis.get_ylim() for
col_axis in row_axis]))]
y_new = np.max(y_new)
for row_axis in axes:
[col_axis.set_ylim(-y_new,y_new) for col_axis in row_axis]
plt.show()
def show_features_2D(data, cmap='bwr', norm=None,
scale_width=1, scale_height=1):
if norm is not None:
vmin, vmax = norm
else:
vmin, vmax = None, None
plt.imshow(data, cmap=cmap, vmin=vmin, vmax=vmax)
plt.xlabel('Timesteps', weight='bold', fontsize=14)
plt.ylabel('Attention features', weight='bold', fontsize=14)
plt.colorbar(fraction=0.046, pad=0.04)
plt.gcf().set_size_inches(8*scale_width, 8*scale_height)
plt.show()
def get_layer_outputs(model, layer_name, input_data, learning_phase=1):
outputs = [layer.output for layer in model.layers if layer_name in layer.name]
layers_fn = K.function([model.input, K.learning_phase()], outputs)
return layers_fn([input_data, learning_phase])
SeqWeightedAttention示例按要求提供:
ipt = Input(batch_shape=(10,240,4))
x = LSTM(60, activation='tanh', return_sequences=True)(ipt)
x = SeqWeightedAttention(return_attention=True)(x)
x = concatenate(x)
out = Dense(1, activation='sigmoid')(x)
model = Model(ipt,out)
model.compile(Adam(lr=1e-2), loss='binary_crossentropy')
X = np.random.rand(10,240,4)
Y = np.random.randint(0,2,(10,1))
model.train_on_batch(X, Y)
outs = get_layer_outputs(model, 'seq', X, 1)
outs_1 = outs[0][0]
outs_2 = outs[1][0]
plt.hist(outs_1, bins=500); plt.show()
plt.hist(outs_2, bins=500); plt.show()
print(model.layers[1].output.shape)),我仍然可以回答。这个想法将是“分而治之”。 - OverLordGoldDragonreturn_attention=True- 是吗?否则,该层似乎只应用了一个转换,无法有意义地分成两个。 - OverLordGoldDragonconcatenate层。此外,我强烈建议大多数情况下使用Model API(Model),因为它更容易使用高级功能 - 但Sequential在这里也可以工作。所以确认一下:return_attention=True返回两个输出,这两个是你所指的吗?如果是的话,我将用完整的示例更新答案。 - OverLordGoldDragon