使用H2O Python模块AutoML后,发现XGBoost位于排行榜的首位。然后我尝试从H2O XGBoost中提取超参数,并在XGBoost Sklearn API中进行复制。但是,这两种方法的性能不同:
from sklearn import datasets
from sklearn.model_selection import train_test_split, cross_val_predict
from sklearn.metrics import classification_report
import xgboost as xgb
import scikitplot as skplt
import h2o
from h2o.automl import H2OAutoML
import numpy as np
import pandas as pd
h2o.init()
iris = datasets.load_iris()
X = iris.data
y = iris.target
data = pd.DataFrame(np.concatenate([X, y[:,None]], axis=1))
data.columns = iris.feature_names + ['target']
data = data.sample(frac=1)
# data.shape
train_df = data[:120]
test_df = data[120:]
# Import a sample binary outcome train/test set into H2O
train = h2o.H2OFrame(train_df)
test = h2o.H2OFrame(test_df)
# Identify predictors and response
x = train.columns
y = "target"
x.remove(y)
# For binary classification, response should be a factor
train[y] = train[y].asfactor()
test[y] = test[y].asfactor()
aml = H2OAutoML(max_models=10, seed=1, nfolds = 3,
keep_cross_validation_predictions=True,
exclude_algos = ["GLM", "DeepLearning", "DRF", "GBM"])
aml.train(x=x, y=y, training_frame=train)
# View the AutoML Leaderboard
lb = aml.leaderboard
lb.head(rows=lb.nrows)
model_ids = list(aml.leaderboard['model_id'].as_data_frame().iloc[:,0])
m = h2o.get_model([mid for mid in model_ids if "XGBoost" in mid][0])
# m.params.keys()
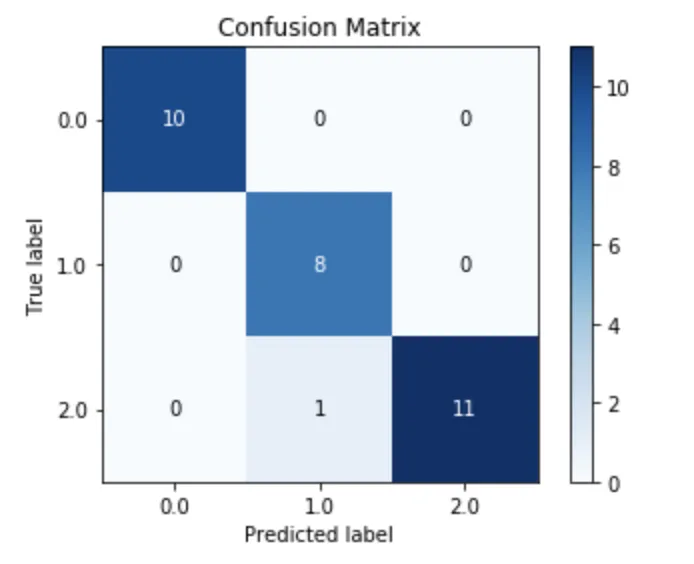
- H2O Xgboost的性能
skplt.metrics.plot_confusion_matrix(test_df['target'],
m.predict(test).as_data_frame()['predict'],
normalize=False)
- 在XGBoost Sklearn API中复制:
mapping_dict = {
"booster": "booster",
"colsample_bylevel": "col_sample_rate",
"colsample_bytree": "col_sample_rate_per_tree",
"gamma": "min_split_improvement",
"learning_rate": "learn_rate",
"max_delta_step": "max_delta_step",
"max_depth": "max_depth",
"min_child_weight": "min_rows",
"n_estimators": "ntrees",
"nthread": "nthread",
"reg_alpha": "reg_alpha",
"reg_lambda": "reg_lambda",
"subsample": "sample_rate",
"seed": "seed",
# "max_delta_step": "score_tree_interval",
# 'missing': None,
# 'objective': 'binary:logistic',
# 'scale_pos_weight': 1,
# 'silent': 1,
# 'base_score': 0.5,
}
parameter_from_water = {}
for item in mapping_dict.items():
parameter_from_water[item[0]] = m.params[item[1]]['actual']
# parameter_from_water
xgb_clf = xgb.XGBClassifier(**parameter_from_water)
xgb_clf.fit(train_df.drop('target', axis=1), train_df['target'])
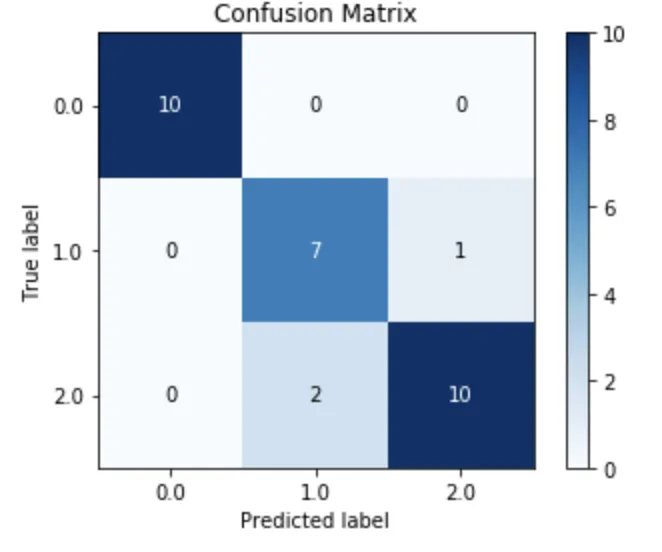
- Sklearn XGBoost的性能:
(在我尝试的所有示例中,性能始终比H2O差.)
skplt.metrics.plot_confusion_matrix(test_df['target'],
xgb_clf.predict(test_df.drop('target', axis=1) ),
normalize=False);
是否有任何明显的遗漏?
train_df和test_df? - Yuan JI