我在这里读到增强for循环比普通的for循环更有效率:
但这是增强型for循环比普通for循环好的唯一原因吗?在这种情况下,最好使用普通的“for循环”来理解增强的“for循环”,因为它略微复杂。
http://developer.android.com/guide/practices/performance.html#foreach
当我搜索它们效率的差异时,发现的唯一不同之处是:在普通的for循环中,我们需要额外的步骤来找出数组或大小的长度等信息。
for(Integer i : list){
....
}
int n = list.size();
for(int i=0; i < n; ++i){
....
}
但这是增强型for循环比普通for循环好的唯一原因吗?在这种情况下,最好使用普通的“for循环”来理解增强的“for循环”,因为它略微复杂。
查看此处以获取有趣的问题:http://www.coderanch.com/t/258147/java-programmer-SCJP/certification/Enhanced-Loop-Vs-Loop
能否有人请解释这两种类型的for循环的内部实现,或者解释使用增强的“for循环”的其他原因?
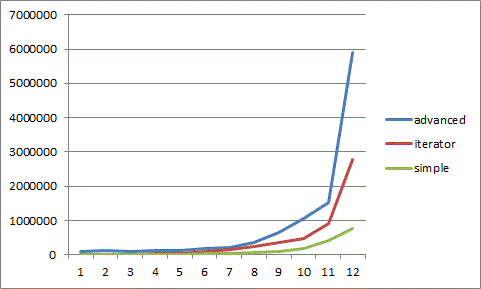
zero()是最慢的,因为JIT还不能优化掉每次迭代循环时获取数组长度的开销。” 对我来说,这看起来像是一个解释。 - Joachim Sauer