这是我的问题:
我希望生成类似于
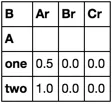
例如,对于'C'列中对应值为1和0的'one'和'Ar'两种情况,我们将'C'列中的值相加(0+1),并除以'C'列中的值的数量,因此我们得到(0+1)/2=0.5。当组合不存在时(例如'Cr'和'one'),我们将其设置为零。有什么想法吗?
df = pd.DataFrame({'A': ['one', 'one', 'two', 'two', 'one'] ,
'B': ['Ar', 'Br', 'Cr', 'Ar','Ar'] ,
'C': [1, 0, 0, 1,0 ]})
我希望生成类似于
pd.crosstab函数的输出,但是列和行交叉点上的值应该来自第三列的聚合结果: Ar, Br, Cr
one 0.5 0 0
two 1 0 0
例如,对于'C'列中对应值为1和0的'one'和'Ar'两种情况,我们将'C'列中的值相加(0+1),并除以'C'列中的值的数量,因此我们得到(0+1)/2=0.5。当组合不存在时(例如'Cr'和'one'),我们将其设置为零。有什么想法吗?
pivot_table()正是在幕后完成了这个任务(还有一些额外的操作)…… ;) - MaxU - stand with Ukraine