假设我有一个DataFrame,其第一列是随机数,其他列将基于前一列的值。
下面是我的(失败的)尝试:
apply()或rolling_apply()完成此操作?或者,如何以其他更有效的方式完成?下面是我的(失败的)尝试:
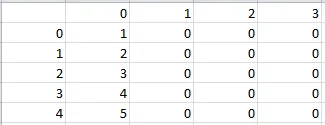
In [12]: a = pandas.DataFrame({0:[1,2,3,4,5],1:0,2:0,3:0})
In [13]: a
Out[13]:
0 1 2 3
0 1 0 0 0
1 2 0 0 0
2 3 0 0 0
3 4 0 0 0
4 5 0 0 0
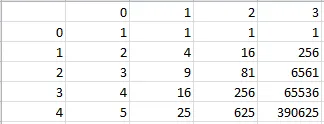
In [14]: a = a.apply(lambda x: x**2)
In [15]: a
Out[15]:
0 1 2 3
0 1 0 0 0
1 4 0 0 0
2 9 0 0 0
3 16 0 0 0
4 25 0 0 0
In [16]: a = pandas.DataFrame({0:[1,2,3,4,5],1:0,2:0,3:0})
In [17]: pandas.rolling_apply(a,1,lambda x: x**2)
C:\WinPython64bit\python-3.5.2.amd64\lib\site-packages\spyderlib\widgets\externalshell\start_ipython_kernel.py:1: FutureWarning: pd.rolling_apply is deprecated for DataFrame and will be removed in a future version, replace with
DataFrame.rolling(center=False,window=1).apply(args=<tuple>,kwargs=<dict>,func=<function>)
# -*- coding: utf-8 -*-
Out[17]:
0 1 2 3
0 1.0 0.0 0.0 0.0
1 4.0 0.0 0.0 0.0
2 9.0 0.0 0.0 0.0
3 16.0 0.0 0.0 0.0
4 25.0 0.0 0.0 0.0
In [18]: a = pandas.DataFrame({0:[1,2,3,4,5],1:0,2:0,3:0})
In [19]: a = a[:-1]**2
In [20]: a
Out[20]:
0 1 2 3
0 1 0 0 0
1 4 0 0 0
2 9 0 0 0
3 16 0 0 0
In [21]:
所以,我的问题主要是如何在DataFrame计算中引用前一列的值。