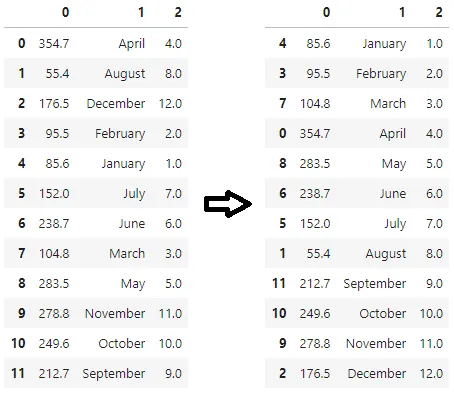
使用键进行排序
自从pandas 1.1.0版本以后,我们可以传递一个key=参数,该参数接受一个函数作为排序键,就像Python内置的sorted()函数中的key参数一样。然而,与传递给sorted函数的键函数不同的是,这个函数必须是矢量化的,也就是说它必须输出一个Series/DataFrame来用于排序输入。
对于OP中的示例,我们可以直接对列'1'应用排序键,而不是创建列'2'来按列'1'排序。因为作为by=参数传递的列在.sort_values()内部进行操作,我们可以创建一个月份名称到数字的映射字典,并传递一个lambda函数将这个字典映射到列'1'。
import calendar
month_to_number_mapper = {m:i for i,m in enumerate(calendar.month_name)}
df1 = df.sort_values(by='1', key=lambda col: col.map(month_to_number_mapper))
正如你所看到的,这让人想起了在纯Python中使用
sorted()函数的调用。
li = sorted(df.values, key=lambda row: month_to_number_mapper[row[1]])
对于OP中的示例,由于列'1'是一个月份名称的列,我们可以将其视为日期时间列来对数据框进行排序。为了做到这一点,我们可以将pandas的to_datetime函数作为关键字传递。
df1 = df.sort_values(by='1', key=lambda col: pd.to_datetime(col, format='%B'))
这让人想起了在纯Python中调用
sorted()的情景。
from datetime import datetime
li = sorted(df.values, key=lambda row: datetime.strptime(row[1], '%B'))
按索引排序
Pandas的.loc[]根据传递给它的值重新排列行。因此,另一种排序的方法是使用任何排序键对列'1'进行排序,然后将排序后的对象的索引传递给loc[]。
sorted_index = pd.to_datetime(df['1'], format='%B').sort_values().index
df1 = df.loc[sorted_index]
所有上述列出的三种方式都执行以下转换: