我非常关注MySQL索引的工作原理,更具体地说,如何在不扫描整个表的情况下返回请求的数据?
虽然这与主题无关,但如果有人能够详细解释给我听,我将非常感激。
基本上,表中的索引就像书中的索引(这也是名称的由来):
假设你有一本关于数据库的书,想要查找一些关于存储的信息。如果没有索引(假设没有其他辅助工具,如目录),你需要一页一页地翻阅,直到找到该主题(这就是全表扫描)。另一方面,索引有一个关键字列表,因此您可以查询索引并查看到 storage 出现在113-120页、231页和354页。然后,您可以直接翻到这些页面,而无需搜索(这是一种使用索引进行查找,速度较快的方法)。
当然,索引的实用程度取决于许多因素 - 以下是一些示例,使用上述比喻:
首先,你必须知道的是索引是一种避免扫描整个表格以获取所需结果的方法。
有不同类型的索引,并且它们在存储层中实现,因此它们之间没有标准,也取决于您使用的存储引擎。
对于InnoDB,最常见的索引类型是基于B+树的索引,它按排序顺序存储元素。此外,您无需访问真实表格即可获取索引值,从而使查询返回更快。
这种索引类型的“问题”是您必须查询左侧的值才能使用该索引。因此,如果您的索引有两个列,例如last_name和first_name,查询这些字段的顺序非常重要。
因此,考虑以下表格:
CREATE TABLE person (
last_name VARCHAR(50) NOT NULL,
first_name VARCHAR(50) NOT NULL,
INDEX (last_name, first_name)
);
这个查询将利用索引:
SELECT last_name, first_name FROM person
WHERE last_name = "John" AND first_name LIKE "J%"
SELECT last_name, first_name FROM person WHERE first_name = "Constantine"
由于您首先查询了first_name列,而它并不是索引中最左边的列。
这个最后的例子甚至更糟:
SELECT last_name, first_name FROM person WHERE first_name LIKE "%Constantine"
因为现在,你正在比较索引中最右侧字段的最右侧部分。
这是一种不同类型的索引,可惜只有内存后端支持。它非常快速,但仅适用于完全查找,这意味着您无法将其用于像 >、< 或 LIKE 这样的操作。
由于它仅适用于内存后端,您可能不会经常使用它。我现在能想到的主要情况是,在内存中创建一个临时表格,其中包含从另一个 select 中获得的一组结果,并在该临时表格中使用哈希索引执行许多其他 selects。
如果您有一个很大的 VARCHAR 字段,当使用 B-Tree 时,可以通过创建另一个列并在其上保存大值的哈希值来“模拟”使用哈希索引。假设您正在将 url 存储在一个字段中,这些值相当大。您还可以创建一个名为 url_hash 的整数字段,并使用诸如 CRC32 或任何其他哈希函数来哈希插入的 url。然后,当您需要查询此值时,可以执行以下操作:
SELECT url FROM url_table WHERE url_hash=CRC32("http://gnu.org");
上述示例的问题在于CRC32函数生成的哈希值相对较小,因此在哈希值中会产生许多冲突。如果您需要精确的值,可以通过执行以下操作来解决此问题:
SELECT url FROM url_table
WHERE url_hash=CRC32("http://gnu.org") AND url="http://gnu.org";
即使碰撞数很高,哈希仍然值得使用,因为你只需要对重复哈希执行第二个比较(字符串比较)。
不幸的是,使用这种技术,你仍然需要访问表来比较url字段。
每次谈论优化时,可以考虑以下几点:
整数比较比字符串比较快得多。可以用InnoDB中模拟哈希索引的示例来说明。
也许在一个过程中添加额外的步骤会使它更快,而不是更慢。这可以通过将SELECT优化为两个步骤来说明,使第一个步骤将值存储到新创建的内存表中,然后在这个第二个表上执行更重的查询。
MySQL还有其他的索引,但我认为B+Tree是最常用的索引类型,哈希索引也是了解的好东西,但您可以在MySQL文档中找到其他索引。
我强烈推荐您阅读《高性能MySQL》一书,上述答案绝对是基于其中关于索引的章节。
SELECT last_name, first_name FROM person WHERE last_name= "Constantine"SELECT last_name, first_name FROM person WHERE last_name LIKE "%Constantine"utf8mb4,整个字段占用3072字节)。如果我使用建议的CRC32哈希,我可以通过在仅使用4个字节的整数字段(CRC32)上创建索引来实现类似的结果,而不是现在使用的每个字段3072字节! - Rafay索引基本上是一个按顺序排列的所有键的映射表。有了排序好的列表,它就可以执行以下操作而不是检查每个键:
1:进入列表中间位置——比我要查找的键高还是低?
2:如果高,前往中间点和底部之间的中点;如果低,前往中间点和顶部之间的中点。
3:高还是低?再次跳转到中间点,并重复上述步骤。
使用这种逻辑,你可以在大约7个步骤内找到已排序列表中的元素,而无需检查每个项。
显然,还有一些复杂性,但这给出了基本想法。
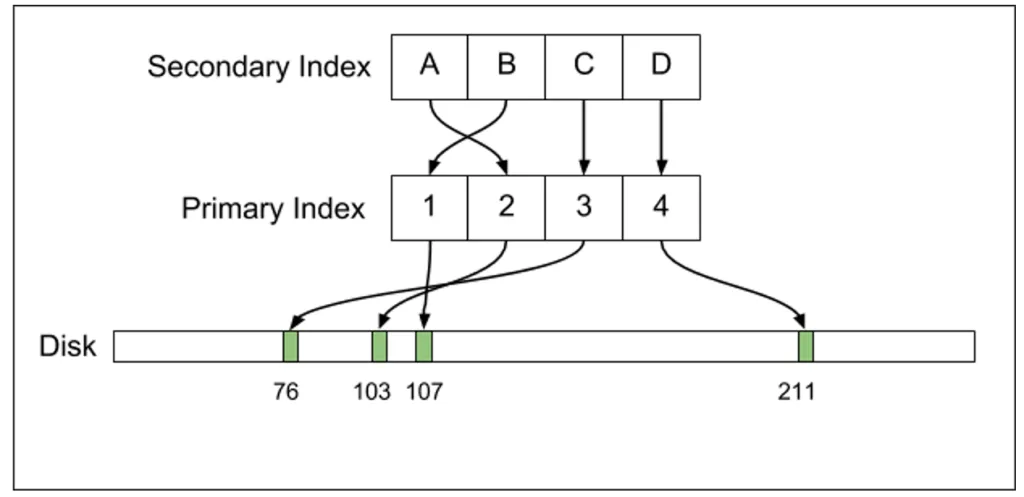 MySQL使用额外的间接层:二级索引记录指向主索引记录,而主索引本身保存在磁盘上的行位置。如果行偏移量更改,则只需更新主索引。
MySQL使用额外的间接层:二级索引记录指向主索引记录,而主索引本身保存在磁盘上的行位置。如果行偏移量更改,则只需更新主索引。点击此链接查看有关索引的更多详细信息。
简单索引 您可以在表上创建唯一索引。唯一索引意味着两行不能具有相同的索引值。以下是在表上创建索引的语法:
CREATE UNIQUE INDEX index_name
ON table_name ( column1, column2,...);
您可以使用一个或多个列创建索引。例如,我们可以使用tutorial_author在tutorials_tbl上创建一个索引。
CREATE UNIQUE INDEX AUTHOR_INDEX
ON tutorials_tbl (tutorial_author)
mysql> CREATE UNIQUE INDEX AUTHOR_INDEX
ON tutorials_tbl (tutorial_author DESC)
我想要发表我的意见。虽然我不是一个数据库专家,但最近我阅读了一些相关的文章;这让我有足够的知识尝试用通俗易懂的语言来解释。以下是我个人的解释。
索引用于快速查找具有特定列值的行。如果没有索引,MySQL必须从第一行开始,然后读取整个表以查找相关行。表越大,成本就越高。如果表中有涉及的列的索引,MySQL可以快速确定要在数据文件中寻找的位置,而无需查看所有数据。这比按顺序阅读每一行要快得多。
索引添加了一个带有搜索条件和指针列的数据结构
指针是具有其余信息的行的内存磁盘地址
索引数据结构已排序以优化查询效率
查询在索引中查找特定行;索引引用指针,该指针将找到其余信息。
索引将查询需要搜索的行数从17减少到4。
SELECT * FROM members WHERE id = '1'- 所以为什么使用索引会更快?这个索引在这里起到了什么作用? - good_evening