我有一个拥有奇怪样式的xls文件,但是我无能为力,只需要解析它。
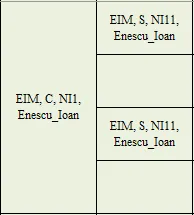
如您所见,我有一些合并的单元格。我想要做的是填充合并单元格中的空值("ffill"),但同时保留空单元格原样。
像这样
EIM, C,NI1 Enescu_Ioan, EIM, S,NI11,Enescu_Ioan
EIM, C,NI1 Enescu_Ioan, Empty
EIM, C,NI1 Enescu_Ioan EIM, S,NI11,Enescu_Ioan
EIM, C,NI1,Enescu_Ioan Empty
我现在加载文件的方式如下:
xl = pd.ExcelFile("data/file.xls")
df = xl.parse(0, header=None)
我也尝试以这种方式打开文件并访问合并单元格,但是我得到了一个空列表。
book = xlrd.open_workbook("data/file.xls")
book.sheet_by_index(0).merged_cells # This is empty []
有没有办法实现这个?谢谢!
编辑
关于问题可能会有一些混淆,所以我会尽量更好地解释。附加的图像是一个更大文件的子集,其中列可能以不同的顺序出现。我试图实现的是区分合并单元格NAN值(在合并单元格中只有第一列有值,其余都是nan)和空单元格NAN的方法。