我在Windows上运行Python 2.7。
我有一个大文本文件(2 GB),其中涉及50万多封电子邮件。该文件没有明确的文件类型,格式如下:
email_message#: 1
email_message_sent: 10/10/1991 02:31:01
From: tomf@abc.com| Tom Foo |abc company|
To: adee@abc.com| Alex Dee |abc company|
To: benfor12@xyz.com| Ben For |xyz company|
email_message#: 2
email_message_sent: 10/12/1991 01:28:12
From: timt@abc.com| Tim Tee |abc company|
To: tomf@abc.com| Tom Foo |abc company|
To: adee@abc.com| Alex Dee |abc company|
To: benfor12@xyz.com| Ben For|xyz company|
email_message#: 3
email_message_sent: 10/13/1991 12:01:16
From: benfor12@xyz.com| Ben For |xyz company|
To: tomfoo@abc.com| Tom Foo |abc company|
To: t212@123.com| Tatiana Xocarsky |numbers firm |
...
如您所见,每个电子邮件都与以下数据相关:
1) 发送时间
2) 发件人电子邮件地址
3) 发件人姓名
4) 发件人所在公司
5) 所有收件人电子邮件地址
6) 每个收件人的姓名
7) 每个收件人所在公司
文本文件中有500K+封电子邮件,每封邮件最多可有16K个收件人。这些电子邮件中关于人名或工作公司的称呼没有规律可循。
我想使用python操作这个大文件,并将其转换为Pandas Dataframe。我希望pandas dataframe的格式类似于下面的excel截图:
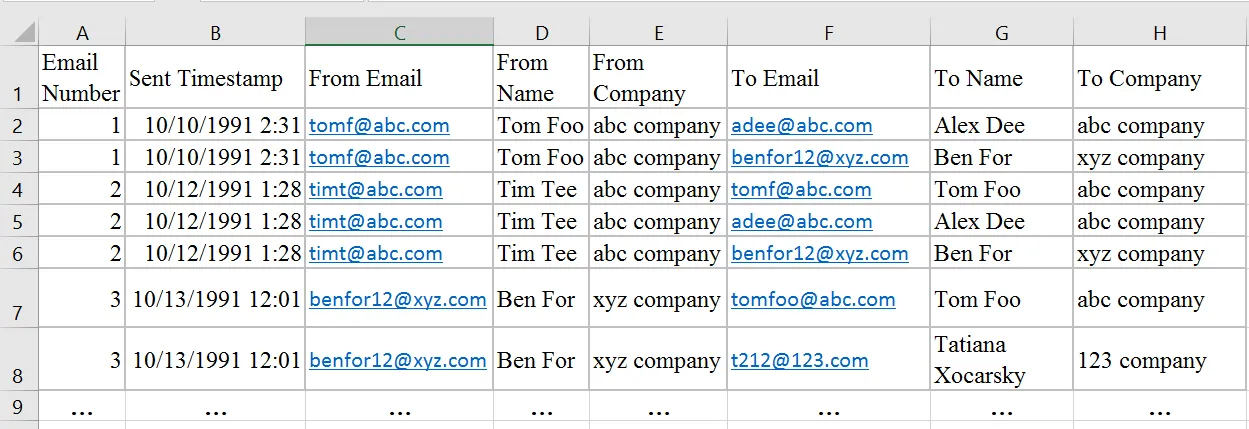
编辑
我的解决方案是编写一个“解析器”,它会读取这个文本文件并逐行读入,将每行中的文本分配到 pandas dataframe 的特定列中。
我计划编写类似下面的代码。有人能确认这是执行此操作的正确方法吗?我想确保我没有错过任何内置的 pandas 函数或来自不同 module 的函数。
#connect to object
data = open('.../Emails', 'r')
#build empty dataframe
import pandas as pd
df = pd.DataFrame()
#function to read lines of the object and put pieces of text into the
# correct column of the dataframe
for line in data:
n = data.readline()
if n.startswith("email_message#:"):
#put a slice of the text into a dataframe
elif n.startswith("email_message_sent:"):
#put a slice of the text into a dataframe
elif n.startswith("From:"):
#put slices of the text into a dataframe
elif n.startswith("To:"):
#put slices of the text into a dataframe