回答这个问题花费了一些时间,但我必须把所有的内容写出来并进行测试!
我处理过的数据:
begin
insert into student(id, name) values (1, 'Tom');
insert into student(id, name) values (2, 'Odysseas');
insert into class(id, subject) values (1, 'Programming');
insert into class(id, subject) values (2, 'Databases');
insert into class_meeting (id, class_id, meeting_sequence) values (1, 1, 10);
insert into class_meeting (id, class_id, meeting_sequence) values (2, 1, 20);
insert into class_meeting (id, class_id, meeting_sequence) values (3, 2, 10);
insert into class_meeting (id, class_id, meeting_sequence) values (4, 2, 20);
insert into meeting_attendance (id, student_id, meeting_id, present) values (1, 1, 1, 1);
insert into meeting_attendance (id, student_id, meeting_id, present) values (2, 1, 2, 1);
insert into meeting_attendance (id, student_id, meeting_id, present) values (3, 1, 3, 0);
insert into meeting_attendance (id, student_id, meeting_id, present) values (4, 1, 4, 0);
insert into meeting_attendance (id, student_id, meeting_id, present) values (5, 2, 1, 0);
insert into meeting_attendance (id, student_id, meeting_id, present) values (6, 2, 2, 1);
insert into meeting_attendance (id, student_id, meeting_id, present) values (7, 2, 3, 0);
insert into meeting_attendance (id, student_id, meeting_id, present) values (8, 2, 4, 1);
end;
目前,PIVOT不能以简单的方式动态地允许列数。它只能使用XML关键字实现,从而导致xmltype列。 这里有一些很好的文档。http://www.oracle-base.com/articles/11g/pivot-and-unpivot-operators-11gr1.php
阅读这些文档总是值得的。
那么,该怎么做呢?
一旦开始搜索,您会发现有很多关于同样问题的问题。
动态SQL
经典报告可以采用返回 SQL 语句的函数体作为返回。交互式报告则不行。目前,IR是不可能的,因为它太过于元数据依赖。
例如,在经典报告区域的源中使用以下查询/PLSQL:
静态透视表
select *
from (
select s.name as student_name, m.present present, cm.meeting_sequence||'-'|| c.subject meeting
from student s
join meeting_attendance m
on s.id = m.student_id
join class_meeting cm
on cm.id = m.meeting_id
join class c
on c.id = cm.class_id
)
pivot ( max(present) for meeting in ('10-Databases' as "10-DB", '20-Databases' as "20-DB", '10-Programming' as "10-PRM", '20-Programming' as "20-PRM") );
STUDENT_NAME '10-Databases' 20-DB 10-PRM 20-PRM
Tom 0 0 1 1
Odysseas 0 1 0 1
函数体返回语句
DECLARE
l_pivot_cols VARCHAR2(4000);
l_pivot_qry VARCHAR2(4000);
BEGIN
SELECT ''''||listagg(cm.meeting_sequence||'-'||c.subject, ''',''') within group(order by 1)||''''
INTO l_pivot_cols
FROM class_meeting cm
JOIN "CLASS" c
ON c.id = cm.class_id;
l_pivot_qry :=
'select * from ( '
|| 'select s.name as student_name, m.present present, cm.meeting_sequence||''-''||c.subject meeting '
|| 'from student s '
|| 'join meeting_attendance m '
|| 'on s.id = m.student_id '
|| 'join class_meeting cm '
|| 'on cm.id = m.meeting_id '
|| 'join class c '
|| 'on c.id = cm.class_id '
|| ') '
|| 'pivot ( max(present) for meeting in ('||l_pivot_cols||') )' ;
RETURN l_pivot_qry;
END;
请注意区域源的设置。
这是标准设置。它会解析您的查询,然后将查询中找到的列存储在报表元数据中。如果您使用上述PL/SQL代码创建报表,则可以看到APEX已解析查询并分配了正确的列。但这种方法的问题在于元数据是静态的。报表的元数据不会在每次运行报表时刷新。
这可以通过在数据中添加另一个类别来简单地证明。
begin
insert into class(id, subject) values (3, 'Watch YouTube');
insert into class_meeting (id, class_id, meeting_sequence) values (5, 3, 10);
insert into meeting_attendance (id, student_id, meeting_id, present) values (10, 1, 5, 1);
end;
不要编辑报告就运行页面! 编辑和保存将重新生成元数据,这显然不是一种可行的方法。数据无论如何都会发生改变,您不能每次都进入并保存报告元数据。
begin
delete from class where id = 3;
delete from class_meeting where id = 5;
delete from meeting_attendance where id = 10;
end;
将源设置为此类型将使您采用更动态的方法。通过将报表的设置更改为此解析类型,Apex 将在其元数据中生成一定数量的列,而不直接关联实际查询。它们只是具有“COL1”、“COL2”、“COL3”等列名称。
运行报表。效果良好。现在再插入一些数据。
begin
insert into class(id, subject) values (3, 'Watch YouTube');
insert into class_meeting (id, class_id, meeting_sequence) values (5, 3, 10);
insert into meeting_attendance (id, student_id, meeting_id, present) values (10, 1, 5, 1);
end;
运行报告。工作正常。
然而,问题在于列名不太动态且不太美观。你可以编辑这些列,但它们并不是动态的。没有显示任何类,也不能可靠地将它们的标题设置为一个。再次说这很合理:元数据存在,但是它是静态的。如果您对此方法感到满意,它可能适合您。
但是您可以处理这个问题。在报告的“报告属性”中,您可以选择一个“标题类型”。除了“PL/SQL”之外,它们都是静态的!在这里,您可以编写函数体(或仅调用函数),该函数将返回列标题!
DECLARE
l_return VARCHAR2(400);
BEGIN
SELECT listagg(cm.meeting_sequence||'-'||c.subject, ':') within group(order by 1)
INTO l_return
FROM class_meeting cm
JOIN "CLASS" c
ON c.id = cm.class_id;
RETURN l_return;
END;
第三方解决方案
使用 XML
我自己选择使用 XML 关键字。我使用枢轴使所有行和列都有值,然后再用 XMLTABLE 读取它,最后创建一个 XMLTYPE 列,并将其序列化为 CLOB。
这可能有点高级,但这是我迄今为止使用过几次的技术,效果不错。如果基础数据不太大,速度很快,只需一次 SQL 调用,因此上下文切换不多。我也用它处理了 CUBE 的数据,效果很好。
(注:我在元素上添加的类与主题 1 中经典报表中使用的类相对应,简单的红色)
DECLARE
l_return CLOB;
BEGIN
WITH src AS (
SELECT s.name as student_name, m.present present, cm.meeting_sequence||'-'||c.subject meeting
FROM student s
JOIN meeting_attendance m
ON s.id = m.student_id
JOIN class_meeting cm
ON cm.id = m.meeting_id
JOIN class c
ON c.id = cm.class_id
),
src_pivot AS (
SELECT student_name, meeting_xml
FROM src pivot xml(MAX(NVL(present, 0)) AS is_present_max for (meeting) IN (SELECT distinct meeting FROM src) )
),
pivot_html AS (
SELECT student_name
, xmlagg(
xmlelement("td", xmlattributes('data' as "class"), is_present_max)
ORDER BY meeting
) is_present_html
FROM src_pivot
, xmltable('PivotSet/item'
passing meeting_xml
COLUMNS "MEETING" VARCHAR2(400) PATH 'column[@name="MEETING"]'
, "IS_PRESENT_MAX" NUMBER PATH 'column[@name="IS_PRESENT_MAX"]')
GROUP BY (student_name)
),
html_headers AS (
SELECT xmlelement("tr",
xmlelement("th", xmlattributes('header' as "class"), 'Student Name')
, xmlagg(xmlelement("th", xmlattributes('header' as "class"), meeting) order by meeting)
) headers
FROM (SELECT DISTINCT meeting FROM src)
),
html_src as (
SELECT
xmlagg(
xmlelement("tr",
xmlelement("td", xmlattributes('data' as "class"), student_name)
, ah.is_present_html
)
) data
FROM pivot_html ah
)
SELECT
xmlserialize( content
xmlelement("table"
, xmlattributes('report-standard' as "class", '0' as "cellpadding", '0' as "cellspacing", '0' as "border")
, xmlelement("thead", headers )
, xmlelement("tbody", data )
)
AS CLOB INDENT SIZE = 2
)
INTO l_return
FROM html_headers, html_src ;
htp.prn(l_return);
END;
在APEX中:既然HTML已经构建完成,那么这只能是一个调用包函数并使用HTP.PRN打印的PLSQL区域。
(编辑)OTN论坛上也有一个帖子基本上实现了相同的功能,但不会生成标题等,而是使用APEX功能:
OTN: Matrix report
PLSQL
或者,您可以选择老式的PLSQL路线。您可以从上面的动态SQL中提取body,循环遍历它,并通过使用htp.prn调用来输出表结构。输出标题和其他任何您想要的内容。为了更好的效果,在与您正在使用的主题相对应的元素上添加类。
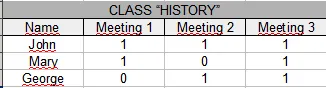 是否可以制作类似的Apex报告?从谷歌搜索中我发现我必须使用Pivot,但是我很难理解它如何在这里使用。以下是我目前拥有的查询:
是否可以制作类似的Apex报告?从谷歌搜索中我发现我必须使用Pivot,但是我很难理解它如何在这里使用。以下是我目前拥有的查询: