我决定为了好玩尝试一些可能性。我拿到一个数据框:
MAX = 10**7
df = pd.DataFrame({'n': range(MAX)})
(这次不是随机的。)我想要找出第一行,其中n >= N对于某个N的值成立。 我计时了以下四个版本:
def getfirst_pandas(condition, df):
return df[condition(df)].iloc[0]
def getfirst_iterrows_loop(condition, df):
for index, row in df.iterrows():
if condition(row):
return index, row
return None
def getfirst_for_loop(condition, df):
for j in range(len(df)):
if condition(df.iloc[j]):
break
return j
def getfirst_numpy_argmax(condition, df):
array = df.as_matrix()
imax = np.argmax(condition(array))
return df.index[imax]
其中N表示10的幂次方。当然,numpy(优化的C语言)代码预计比Python中的for循环更快,但我想看看在哪些N值上,Python循环仍然能够运行良好。
我对这些行计时:
getfirst_pandas(lambda x: x.n >= N, df)
getfirst_iterrows_loop(lambda x: x.n >= N, df)
getfirst_for_loop(lambda x: x.n >= N, df)
getfirst_numpy_argmax(lambda x: x >= N, df.n)
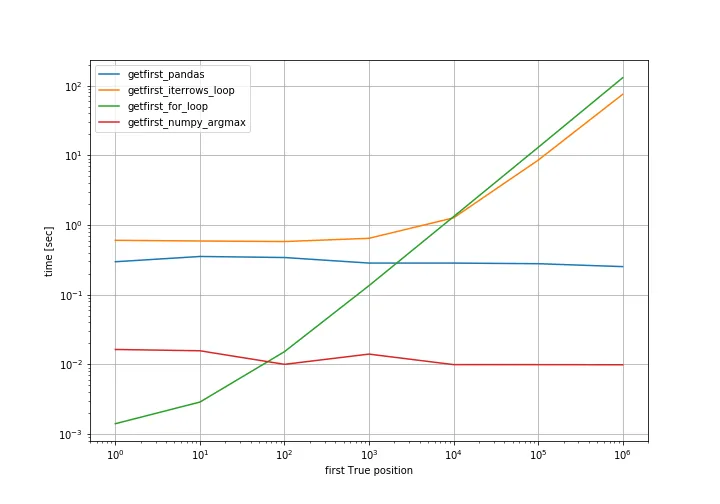
对于N = 1, 10, 100, 1000, ...,这是性能的对数对数图:
图片
简单的for循环只有在"第一个True位置"预期位于开头时才有效,但之后就会变得糟糕。最安全的解决方案是np.argmax。
从图中可以看出,pandas和argmax的时间保持(几乎)不变,因为它们总是扫描整个数组。 最好有一个np或pandas方法不需要扫描整个数组。
{kind=link}
df.iloc[:x,df.A > 3.5].iloc[0]来仅搜索前 X 行。如果这样还是找不到,就继续搜索下一个 X 行,以此类推。根据您的数据和 X 的选择,这应该会很快。否则,我可能会尝试 ayhan 链接中的某个答案中的 numba 函数。 - JohnEdf.n的条件是一个非常广泛的要求,并且根据具体的条件有不同的操作。无论如何,很难避免对系列/列进行逐元素比较。.iloc[0]或者你在末尾添加的任何其他内容都不是昂贵的部分。 - Brad Solomonat和iat而不是loc和iloc。来源:Pandas数据框中迭代行的不同方法-性能比较。 - rocarvaj