我进行了一些测试,比较了C和Java,并发现了一些有趣的事情。将我的完全相同的基准测试代码与优化级别1(-O1)在主函数中调用的函数中运行,而不是在main函数本身中运行,可以将性能提高大约一倍。 我正在打印test_t的大小以确保该代码被编译为x64。
我将可执行文件发送给我的朋友,他正在运行i7-7700HQ,并获得了类似的结果。我正在运行i7-6700。
以下是较慢的代码:
#include <stdio.h>
#include <time.h>
#include <stdint.h>
int main() {
printf("Size = %I64u\n", sizeof(size_t));
int start = clock();
for(int64_t i = 0; i < 10000000000L; i++) {
}
printf("%ld\n", clock() - start);
return 0;
}
同时速度更快:
#include <stdio.h>
#include <time.h>
#include <stdint.h>
void test() {
printf("Size = %I64u\n", sizeof(size_t));
int start = clock();
for(int64_t i = 0; i < 10000000000L; i++) {
}
printf("%ld\n", clock() - start);
}
int main() {
test();
return 0;
}
我也会提供汇编代码给你深入研究。但我不懂汇编语言。 更慢:
.file "dummy.c"
.text
.def __main; .scl 2; .type 32; .endef
.section .rdata,"dr"
.LC0:
.ascii "Size = %I64u\12\0"
.LC1:
.ascii "%ld\12\0"
.text
.globl main
.def main; .scl 2; .type 32; .endef
.seh_proc main
main:
pushq %rbx
.seh_pushreg %rbx
subq $32, %rsp
.seh_stackalloc 32
.seh_endprologue
call __main
movl $8, %edx
leaq .LC0(%rip), %rcx
call printf
call clock
movl %eax, %ebx
movabsq $10000000000, %rax
.L2:
subq $1, %rax
jne .L2
call clock
subl %ebx, %eax
movl %eax, %edx
leaq .LC1(%rip), %rcx
call printf
movl $0, %eax
addq $32, %rsp
popq %rbx
ret
.seh_endproc
.ident "GCC: (x86_64-posix-seh-rev0, Built by MinGW-W64 project) 8.1.0"
.def printf; .scl 2; .type 32; .endef
.def clock; .scl 2; .type 32; .endef
更快:
.file "dummy.c"
.text
.section .rdata,"dr"
.LC0:
.ascii "Size = %I64u\12\0"
.LC1:
.ascii "%ld\12\0"
.text
.globl test
.def test; .scl 2; .type 32; .endef
.seh_proc test
test:
pushq %rbx
.seh_pushreg %rbx
subq $32, %rsp
.seh_stackalloc 32
.seh_endprologue
movl $8, %edx
leaq .LC0(%rip), %rcx
call printf
call clock
movl %eax, %ebx
movabsq $10000000000, %rax
.L2:
subq $1, %rax
jne .L2
call clock
subl %ebx, %eax
movl %eax, %edx
leaq .LC1(%rip), %rcx
call printf
nop
addq $32, %rsp
popq %rbx
ret
.seh_endproc
.def __main; .scl 2; .type 32; .endef
.globl main
.def main; .scl 2; .type 32; .endef
.seh_proc main
main:
subq $40, %rsp
.seh_stackalloc 40
.seh_endprologue
call __main
call test
movl $0, %eax
addq $40, %rsp
ret
.seh_endproc
.ident "GCC: (x86_64-posix-seh-rev0, Built by MinGW-W64 project) 8.1.0"
.def printf; .scl 2; .type 32; .endef
.def clock; .scl 2; .type 32; .endef
这是我的批处理脚本编译代码:
@echo off
set /p file= File to compile:
del compiled.exe
gcc -Wall -Wextra -std=c17 -O1 -o compiled.exe %file%.c
compiled.exe
PAUSE
对于编译为汇编:
@echo off
set /p file= File to compile:
del %file%.s
gcc -S -Wall -Wextra -std=c17 -O1 %file%.c
PAUSE
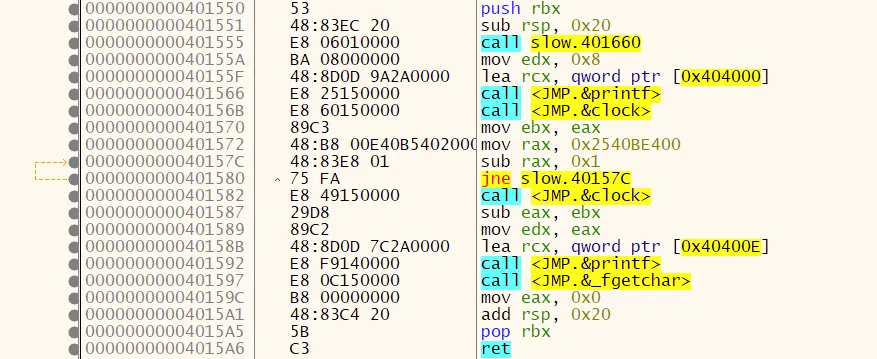

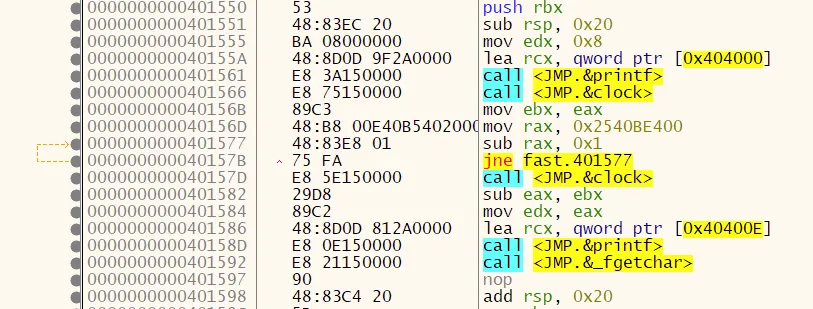
L2的地址,则可以进行检查。 - harold