我在我的Skylake i7-6700HQ上使用Linux perf 进行了一些调查,另一个用户友好地提供了Haswell的结果。以下分析适用于Skylake,但随后与Haswell进行了比较。
其他架构可能会有所不同0,为了帮助梳理这一切,我欢迎额外的结果(源代码可用)。
这个问题主要涉及前端,因为在最近的架构中,前端是强制限制每个周期四个融合域uop的硬性限制。
循环性能规则摘要
首先,我将总结几个“性能规则”,以便在处理小循环时记住。当然还有许多其他的性能规则 - 这些规则是互补的(即,您可能不会打破另一个规则只是为了满足这些规则)。这些规则最直接适用于Haswell和更高版本的架构 - 请参阅其他答案,了解早期架构上的差异概述。
首先,计算您的循环中宏融合 uops的数量。您可以使用Agner的指令表直接查找每个指令,但是ALU uop和紧接着的分支通常会融合成一个单独的uop。然后根据此计数:
- 如果计数是4的倍数,那么很好:这些循环可以执行得最佳。
- 如果计数是偶数且小于32,则除非为10,否则您可以使用另一个偶数卷展。
- 对于奇数,您应该尝试将其展开成小于32或4的倍数的偶数,如果可以的话。
- 对于大于32个uop但小于64个的循环,如果它不是4的倍数,您可能希望展开:对于超过64个uop的循环,在Skylake上任何值都可以获得高效的性能,而在Haswell上几乎所有值都可以(可能有一些偏离,可能与对齐相关)。这些循环的效率损失仍然相对较小:要避免的值最多为
4N + 1 计数,其次是 4N + 2 计数。
研究结果概述
对于从uop缓存中提供的代码,没有明显的4的倍数效应。任何数量的uop循环都可以以每个周期4个融合域uop的吞吐量执行。
对于由传统解码器处理的代码,情况恰好相反:循环执行时间受限于整数个周期,因此不是4个微操作的倍数的循环无法达到每个周期4个微操作,因为它们浪费了一些发射/执行插槽。
对于从循环流检测器(LSD)发出的代码,情况是两者的混合,并在下面进行了更详细的说明。一般来说,小于32个微操作且具有偶数个微操作的循环可以最优地执行,而奇数大小的循环则不能,较大的循环需要多个4个微操作计数才能最优地执行。
英特尔的说法
实际上,英特尔在其优化手册中有关于此的注释,详情请参见其他答案。
细节
正如任何精通最近x86-64架构的人所知,在任何时候,前端的获取和解码部分可能在不同的模式下工作,这取决于代码大小和其他因素。事实证明,这些不同的模式都具有不同的循环大小行为。我将分别介绍它们。
传统解码器
传统解码器1是完整的机器代码到uops解码器,当代码无法适应uop缓存机制(LSD或DSB)时使用2。这种情况发生的主要原因是,如果代码工作集大于uop缓存(在理想情况下约为~1500 uops,在实践中较少)。但是,对于此测试,我们将利用传统解码器的事实,即如果一个对齐的32字节块包含超过18个指令,则也将使用传统解码器3。
为了测试传统解码器的行为,我们使用类似以下的循环:
short_nop:
mov rax, 100_000_000
ALIGN 32
.top:
dec rax
nop
...
jnz .top
ret
基本上,一个简单的循环计数直到rax为零。所有指令都是单个uop4,nop指令的数量在不同大小的循环下(在显示为...的位置)进行变化测试(因此一个4-uop的循环将有2个nop和两个循环控制指令)。我们始终使用至少一个nop将dec和jnz分开,因此没有宏融合,也没有微融合。最后,在隐含的icache访问之外没有内存访问。
请注意,此循环非常密集 - 每个指令约为1字节(因为每个
nop指令都是1字节),因此我们将在循环中触发32B块条件中的> 18个指令,一旦达到19个指令。根据检查
perf性能计数器
lsd.uops和
idq.mite_uops,我们确实看到了这一点:从LSD
5中出来的指令基本上占到了100%,直到包括18 uop循环,但在19个uop及以上,100%来自传统解码器。
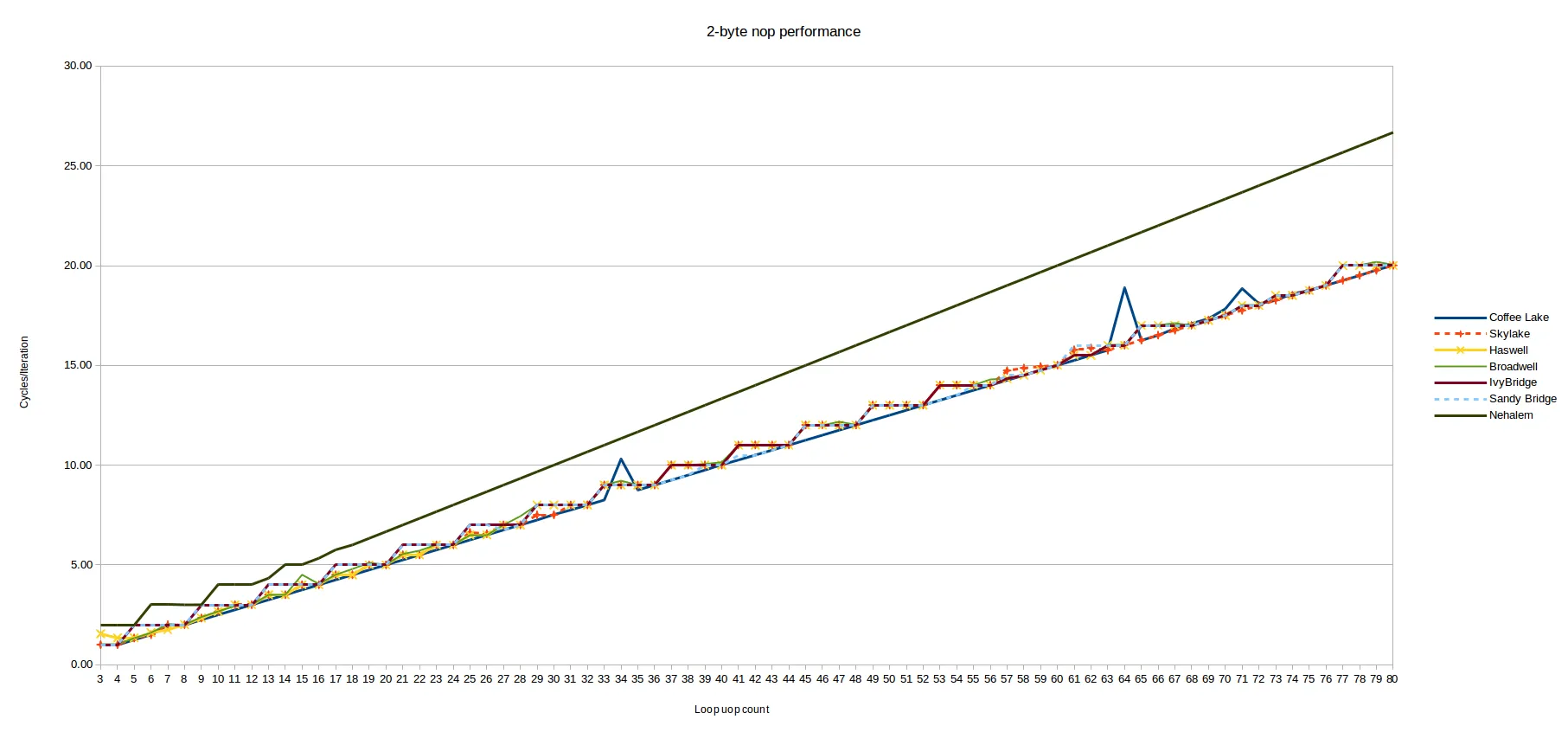
无论如何,以下是所有循环大小从3到99 uops6的每次迭代的周期:

蓝色点是适合于LSD的循环,显示出相当复杂的行为。我们稍后会看这些。
红色点(从每次迭代19个uops开始)由传统解码器处理,并显示出非常可预测的模式:
- 所有具有
N uops的循环都需要ceiling(N/4)次迭代
因此,至少对于传统解码器,在Skylake上Peter的观察完全成立:具有4个uops的倍数的循环可能以IPC 4执行,但任何其他数量的uops都将浪费1、2或3个执行插槽(对于具有4N+3、4N+2、4N+1指令的循环,分别如此)。
我不清楚为什么会出现这种情况。如果你考虑解码发生在连续的16B块中,以每个周期4个微操作的解码速率来看,循环次数不是4的倍数时,总是会在遇到jnz指令时产生一些尾部(浪费)插槽。然而,实际的取指和解码单元由预解码和解码阶段组成,中间有一个队列。预解码阶段实际上具有6条指令的吞吐量,但每个周期仅解码到16字节边界的末尾。这似乎意味着,在循环结束时发生的气泡可以被预解码器- >解码队列吸收,因为预解码器的平均吞吐量高于4。
因此,基于我的对预解码器工作原理的理解,我无法完全解释这一现象。可能存在一些附加的限制,阻止了非整数周期计数的出现。例如,也许传统的解码器不能解码跳转两侧的指令,即使跳转后的指令在预解码队列中可用。也许这与需要处理宏融合有关。
上面的测试显示了循环顶部对齐在32字节边界上的行为。下面是相同的图表,但添加了一个系列,显示当循环顶部向上移动2个字节时的效果(即现在在32N + 30边界处不对齐):
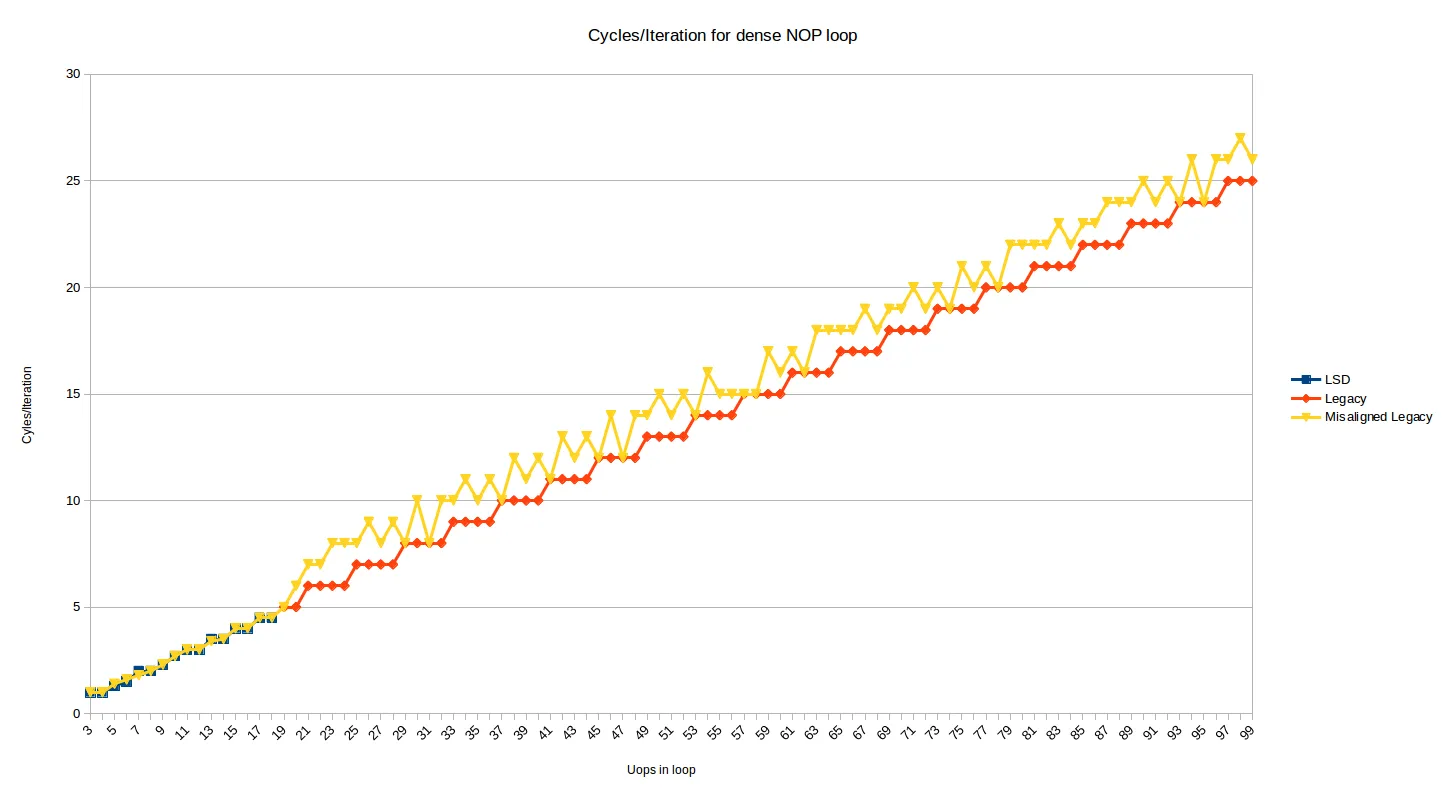
现在大多数循环大小都会受到1或2个周期的惩罚。当您考虑解码16B边界和每个周期解码4条指令时,1个惩罚案例是有道理的,而2个周期的惩罚案例发生在循环中由于某种原因使用DSB进行1个指令(可能是出现在自己的32字节块中的dec指令),并且会产生一些DSB<->MITE切换惩罚。
在某些情况下,错位对于最终对齐循环结束时并不会造成影响。我测试了错位,并且它在200个uop循环中以相同的方式持续存在。如果您按面值接受预解码器的描述,似乎它们应该能够隐藏错位的获取气泡,但这并没有发生(也许队列不够大)。
DSB(Uop缓存)
Uop缓存(英特尔喜欢称其为DSB)能够缓存大多数适度数量指令的循环。在典型程序中,您希望大多数指令都从此缓存中提供7。
我们可以重复上面的测试,但现在从uop缓存中提供uops。这只是一个简单的问题,将我们的nop大小增加到2个字节,这样我们就不再受到18指令限制的影响。我们在循环中使用2字节的nop
xchg ax, ax:
long_nop_test:
mov rax, iters
ALIGN 32
.top:
dec eax
xchg ax, ax
...
xchg ax, ax
jnz .top
ret
在这里,结果非常直观。对于从DSB传递出来的所有测试循环大小,所需的周期数为N/4 - 也就是说,即使它们没有4个uops的倍数,循环也以最大理论吞吐量执行。因此,通常情况下,在Skylake上,从DSB提供的中等大小的循环不需要担心确保uop计数满足某个特定的倍数。
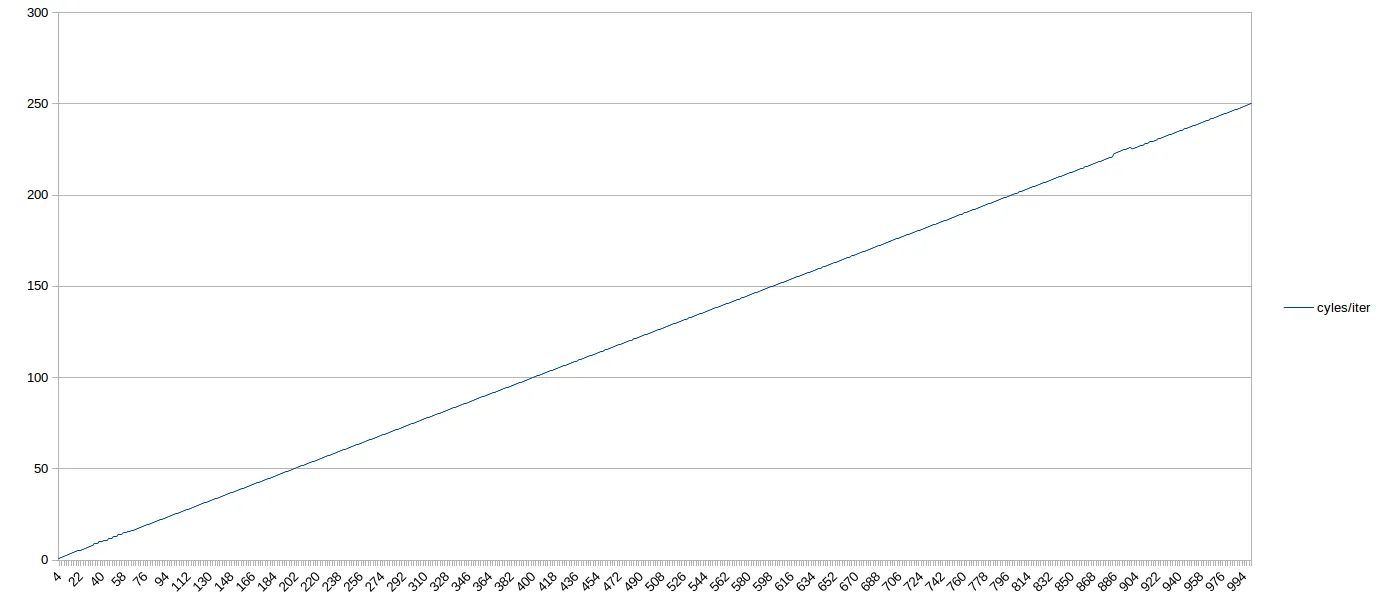
这里有一个图表,展示了1,000个uop循环。如果你眯起眼睛,你可以看到64个uops之前的次优行为。之后,一路顺畅,4 IPC一直到1,000个uops(在900左右有一个小波动,可能是由于我的电脑负载造成的):
接下来我们将关注循环性能,特别是那些足够小以适应uop缓存的循环。
LSD(Loop Stream Detector)
重要提示:英特尔显然通过微码更新在Skylake(SKL150勘误表)和Kaby Lake(KBL095、KBW095勘误表)芯片上禁用了LSD,并且在Skylake-X上默认关闭,原因是与超线程和LSD之间交互相关的错误。对于这些芯片,下面的图表可能不会有64个uops的有趣区域;相反,它看起来只是在64个uops之后的区域一样。
循环流检测器可以缓存最多64个uops的小型循环(在Skylake上)。在英特尔最近的文档中,它被定位为节能机制而不是性能特性-尽管使用LSD肯定没有提到任何性能下降。
对于应该适合LSD的循环大小运行此操作,我们得到以下每次迭代的周期/行为:
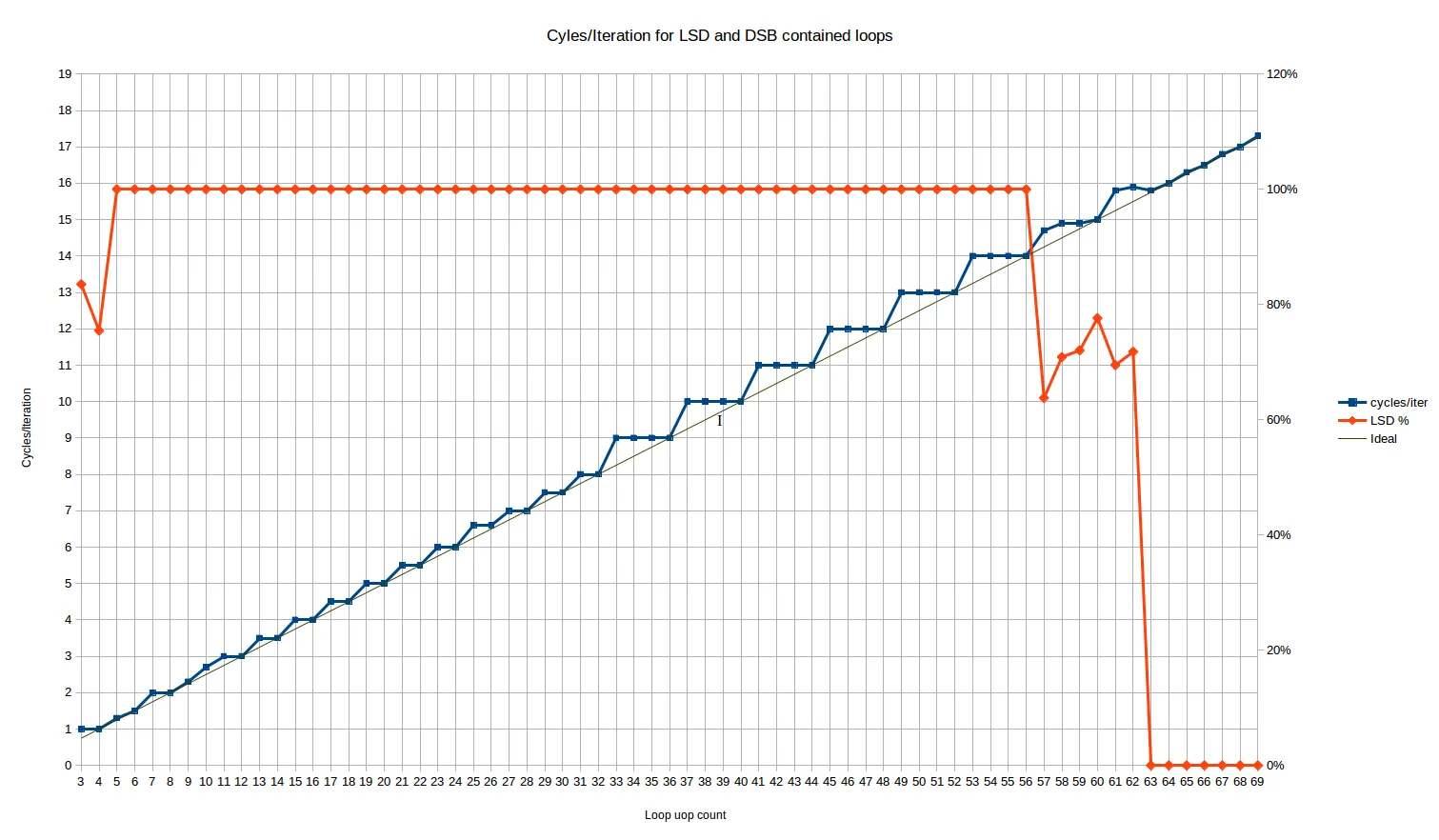
这里的红线是从LSD传递的uops的百分比。对于所有大小在5到56 uops之间的循环,它都保持在100%。
对于3和4 uop循环,我们有一个不寻常的行为,即分别有16%和25%的uops来自传统解码器。什么?幸运的是,这似乎不会影响循环吞吐量,因为两种情况都实现了每个周期的最大吞吐量-尽管人们可能预期会有一些MITE<->LSD转换惩罚。
在57到62 uops的循环大小之间,从LSD传递的uops数量表现出一些奇怪的行为-大约70%的uops来自LSD,其余来自DSB。Skylake名义上具有64-uop LSD,因此这是在超过LSD大小之前的某种过渡-也许在IDQ(LSD所实现的地方)内部存在某种对齐,导致在此阶段仅部分命中LSD。这个阶段很短,从性能上看,似乎主要是完全在LSD性能之前和完全在DSB性能之后的线性组合。
让我们看一下5到56个uops之间的主要结果。我们可以看到三个不同的区域:
3到10个uops的循环:在这里,行为是复杂的。这是唯一一个我们看到不能通过单个循环迭代的静态行为来解释的周期计数区域8。范围太短了,很难说是否存在模式。4、6和8个uops的循环都以N/4个周期的最佳方式执行(这与下一个区域相同)。
另一方面,10个uops的循环每次迭代需要2.66个周期才能执行,这使它成为唯一一个在循环大小达到34个uops或以上(除了26个uops的离群值)之前不会以最佳方式执行的偶数循环大小。这对应于类似于4, 4, 4, 3的重复uop/周期执行速率。对于5个uops的循环,每次迭代需要1.33个周期,非常接近但不完全符合理想的1.25个周期。这对应于执行速率为4, 4, 4, 4, 3。
这些结果很难解释。结果在每次运行中都是可重复的,并且对于诸如将nop替换为实际执行操作的指令(例如mov ecx,123)等更改具有鲁棒性。这可能与每2个周期只能执行1个分支的限制有关,该限制适用于除“非常小”的所有循环以外的所有循环。可能是由于uops偶尔排列在一起,导致此限制生效,从而导致额外的一个周期。一旦达到12个uops或以上,这种情况就不会再发生,因为每次迭代始终需要至少三个周期。
从11到32-uops的循环:我们看到了一种阶梯状的模式,但是周期为二。基本上所有具有
偶数个uop的循环都能够最优化地执行 - 也就是说,需要恰好
N/4个时钟周期。具有奇数个uop的循环浪费了一个“发行槽位”,并且需要与一个uop数量多1的循环(例如,一个17 uop的循环需要和一个18 uop的循环一样花费4.5个时钟周期)相同数量的时钟周期。因此,对于许多uop计数,这里的行为比
ceiling(N/4) 更好,并且我们第一次发现Skylake至少可以以非整数的时钟周期执行循环。
唯一的离群值是N=25和N=26,它们都比预期的长约1.5%。这很小但是可以重复,而且在文件中移动函数后具有鲁棒性。除非它具有巨大的周期,否则每次迭代的效果太小无法解释,所以可能是其他原因。
这里的总体行为(除了25/26的异常情况)与硬件展开循环的因子2完全一致。
从33到~64个微操作的循环:我们再次看到了阶梯状的模式,但是周期为4,并且平均性能比32个微操作以下的情况更差。行为与传统解码器相同,即ceiling(N/4) - 对于32到64个微操作的循环,LSD在这种特定限制下似乎没有比传统解码器提供更多的前端吞吐量优势。当然,LSD有许多其他方面更好-它避免了许多可能出现在更复杂或更长指令中的解码瓶颈,并节省了功率等。
所有这些都非常令人惊讶,因为这意味着从微操作缓存中提供的循环通常在前端执行方面比从LSD提供的循环表现得更好,尽管LSD通常被定位为比DSB更好的微操作源(例如,作为保持循环足够小以适合LSD的建议的一部分)。
这里有另一种观察相同数据的方式 - 以给定uop计数的效率损失为基础,与每个周期的理论最大吞吐量4 uops相比。10%的效率损失意味着您只有从简单的N/4公式计算出来的吞吐量的90%。
整体行为与硬件不执行任何展开操作一致,这是有道理的,因为超过32个uops的循环在64个uops的缓冲区中根本无法展开。
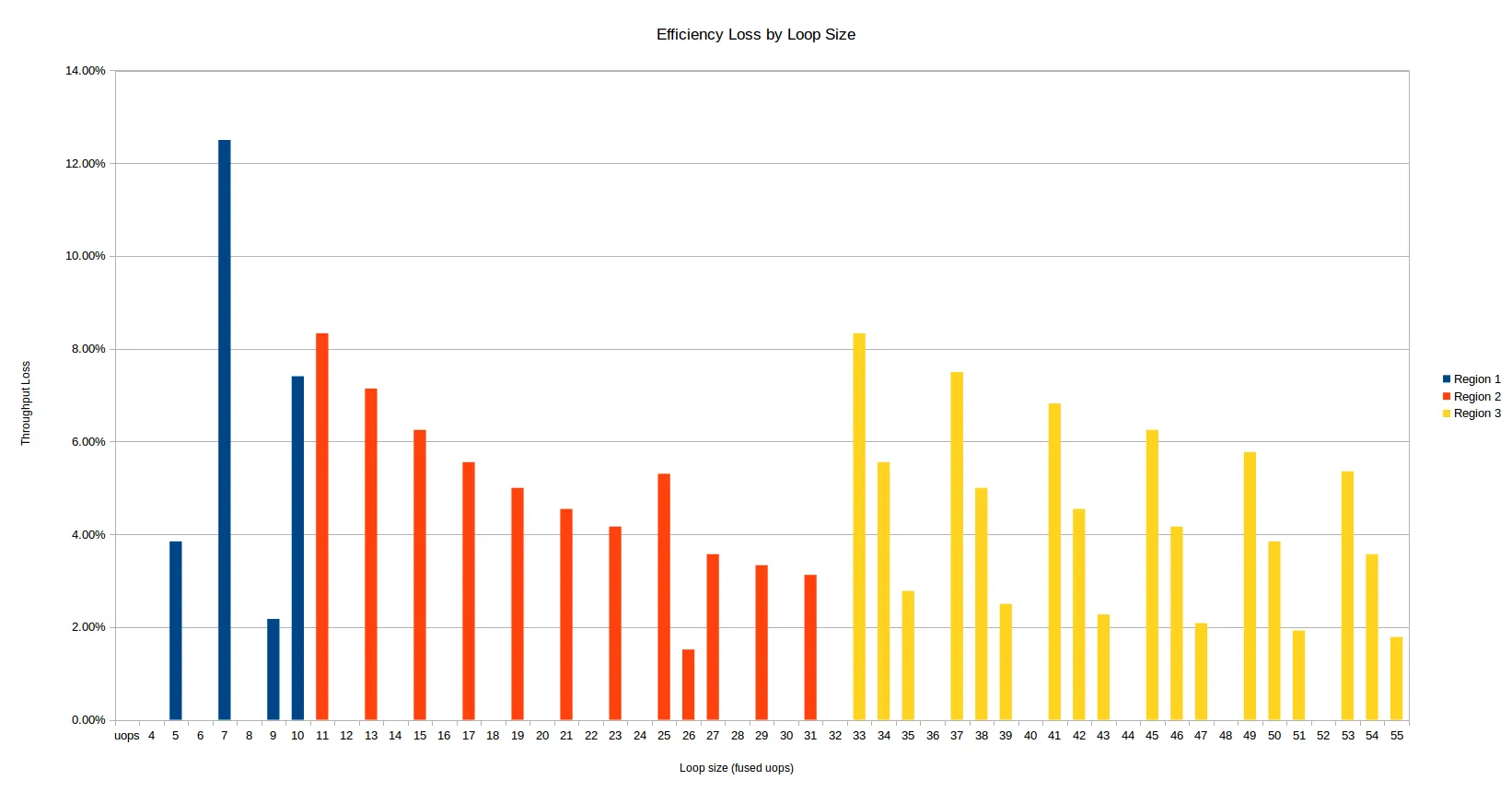
上述三个区域的颜色不同,至少存在竞争效应:
其他条件相同,涉及的uops数量越多,效率损失就越小。该损失是每次迭代的固定成本,因此更大的循环支付较小的相对成本。
当您跨越到33+ uop区域时,效率低下会出现大幅度跳跃:吞吐量损失的大小增加,受影响的uop计数翻倍。
第一个区域有些混乱,7个uops是最差的总体uop计数。
对齐
上面的DSB和LSD分析是针对循环入口对齐到32字节边界的情况,但是未对齐的情况似乎在任何情况下都没有受到影响:与对齐的情况相比,没有实质性的差异(除了可能一些我没有进一步调查的少于10个uops的小变化)。
这里是32N-2和32N+2的未对齐结果(即,在32B边界之前和之后的顶部2个字节的循环):

理想的N/4线也作为参考显示。
Haswell
接下来我们来看一下之前的微架构:Haswell。这里的数字是由用户Iwillnotexist Idonotexist慷慨提供的。
LSD + Legacy Decode Pipeline
首先,我们来看一下“密集代码”测试的结果,该测试测试了LSD(对于小的uop计数)和传统管道(对于较大的uop计数,因为循环由于指令密度而“跳出”DSB)。
我们立即看到一个不同之处,即每个架构何时从LSD中提供uops以进行密集循环。下面我们比较Skylake和Haswell在短循环的密集代码(每个指令1字节)方面的表现。

正如上面所述,与预期的每32字节代码区域18个uop的限制相符,Skylake循环在LSD中停止传递时正好有19个uop。然而,Haswell似乎在16个uop和17个uop的循环中也无法可靠地从LSD中传递。对此我没有任何解释。在3个uop的情况下也存在差异:奇怪的是,这两个处理器在3个uop和4个uop的情况下只传递
一些uop,但4个uop的确切数量与3个不同。
不过,我们更关心实际性能,对吧?那么让我们来看看每个迭代的周期数,针对32字节对齐的
密集代码情况。

这是与 Skylake 相同的数据(已删除不对齐的系列),并将 Haswell 一起绘制。立即注意到 Haswell 的模式是相似的,但不完全相同。与上面一样,这里有两个区域:
传统解码
大于 ~16-18 uops(不确定性在上面描述)的循环来自传统解码器。Haswell 的模式与 Skylake 有些不同。
对于19-30 uops的范围,它们是相同的,但在此之后,Haswell打破了这个模式。Skylake需要ceil(N/4)周期来执行从传统解码器传递的循环。另一方面,Haswell似乎需要类似于ceil((N+1)/4) + ceil((N+2)/12) - ceil((N+1)/12)的东西。好吧,这很混乱(有没有更简洁的形式?)- 但基本上意味着虽然Skylake以4-uops/cycle的速度最优地执行4*N周期的循环,但这样的循环通常是(局部上)最不优的计数(至少在局部上)- 执行这样的循环需要比Skylake多一个周期。因此,在Haswell上,您实际上最好使用4N-1 uops的循环,除非这些循环中25%也是16-1N(31、47、63等)的形式,这些循环需要额外的一个周期。这开始听起来像闰年计算 - 但是这个模式可能最好通过上面的可视化理解。
我认为这种模式不是Haswell上uop调度固有的,所以我们不应该过于解读它。它似乎可以通过以下方式解释:
0000000000455a80 <short_nop_aligned35.top>:
16B cycle
1 1 455a80: ff c8 dec eax
1 1 455a82: 90 nop
1 1 455a83: 90 nop
1 1 455a84: 90 nop
1 2 455a85: 90 nop
1 2 455a86: 90 nop
1 2 455a87: 90 nop
1 2 455a88: 90 nop
1 3 455a89: 90 nop
1 3 455a8a: 90 nop
1 3 455a8b: 90 nop
1 3 455a8c: 90 nop
1 4 455a8d: 90 nop
1 4 455a8e: 90 nop
1 4 455a8f: 90 nop
2 5 455a90: 90 nop
2 5 455a91: 90 nop
2 5 455a92: 90 nop
2 5 455a93: 90 nop
2 6 455a94: 90 nop
2 6 455a95: 90 nop
2 6 455a96: 90 nop
2 6 455a97: 90 nop
2 7 455a98: 90 nop
2 7 455a99: 90 nop
2 7 455a9a: 90 nop
2 7 455a9b: 90 nop
2 8 455a9c: 90 nop
2 8 455a9d: 90 nop
2 8 455a9e: 90 nop
2 8 455a9f: 90 nop
3 9 455aa0: 90 nop
3 9 455aa1: 90 nop
3 9 455aa2: 90 nop
3 9 455aa3: 75 db jne 455a80 <short_nop_aligned35.top>
在这里,我已经记录了16B解码块(1-3),每个指令出现的周期以及它将被解码的周期。规则基本上是解码最多下一个4条指令,只要它们落在当前的16B块中。否则,它们必须等到下一个周期。对于N=35,我们看到在第4个周期中丢失了1个解码槽(只剩下3个指令在16B块中),但除此之外,循环非常好地与16B边界对齐,甚至最后一个周期(9)也可以解码4个指令。
这里是N=36的截断视图,除了循环结束外完全相同:
0000000000455b20 <short_nop_aligned36.top>:
16B cycle
1 1 455a80: ff c8 dec eax
1 1 455b20: ff c8 dec eax
1 1 455b22: 90 nop
... [29 lines omitted] ...
2 8 455b3f: 90 nop
3 9 455b40: 90 nop
3 9 455b41: 90 nop
3 9 455b42: 90 nop
3 9 455b43: 90 nop
3 10 455b44: 75 da jne 455b20 <short_nop_aligned36.top>
现在在第三个和最后一个16B块中有5条指令需要解码,因此需要额外一个周期。基本上35条指令,对于这种特定的指令模式更好地与16B位边界对齐,并且在解码时节省了一个周期。这并不意味着N=35总体上比N=36更好!不同的指令将具有不同的字节数,并且将以不同的方式对齐。类似的对齐问题也解释了每16个字节需要额外的周期:
16B cycle
...
2 7 45581b: 90 nop
2 8 45581c: 90 nop
2 8 45581d: 90 nop
2 8 45581e: 90 nop
3 8 45581f: 75 df jne 455800 <short_nop_aligned31.top>
这里最后的jne指令已经跨越到下一个16字节块(如果一条指令横跨在16字节边界上,那么它实际上属于后一个块),导致了额外的周期损失。这种情况只会在每16个字节中出现一次。
所以Haswell遗留解码器的结果可以完美地解释为已经按照描述进行编程的遗留解码器,例如,Agner Fog的microarchitecture doc。事实上,如果假设Skylake每个周期可以解码5条指令(提供高达5个微操作)9,它似乎也能够解释Skylake的结果。在这种假设下,对于Skylake,该代码的遗留解码吞吐量是渐进式的4-uops,因为16个NOPs组成的块会被解码成5-5-5-1,而不是Haswell的4-4-4-4,因此你只能在边缘获得好处:例如,在上述N=36的情况下,Skylake可以解码所有剩余的5条指令,而Haswell只能解码4-1,从而节省了一个周期。
重点是似乎可以比较简单地理解传统解码器的行为,而主要的优化建议是继续调整代码,使其“聪明地”落入16B对齐的块中(也许像装箱问题那样是NP难的?)。
DSB(和LSD再次)
接下来让我们看一下代码从LSD或DSB提供的情况 - 通过使用“长nop”测试避免破坏每32B块的18-uop限制,因此保留在DSB中。
Haswell vs Skylake:

请注意LSD行为 - 在Haswell中,当达到57个uops时,它停止从LSD中提供,这与LSD大小为57个uops的公布尺寸完全一致。没有像我们在Skylake上看到的奇怪的“过渡期”。对于3和4个uops,Haswell也有奇怪的行为,其中只有约0%和约40%的uops来自LSD。
在性能方面,Haswell通常与Skylake保持一致,但存在一些偏差,例如在65、77和97个uops左右,它会向上舍入到下一个周期,而Skylake即使在产生非整数个周期的情况下仍能每个周期维持4个uops / cycle。在25和26个uops处略有偏差已经消失。也许Skylake的6-uop传递速率有助于避免Haswell由于其4-uop传递速率而遭受的uop-cache对齐问题。
其他架构
以下其他架构的结果由用户Andreas Abel友情提供,但由于我们在字符限制上限,我们将不得不使用另一个答案进行进一步分析。
需要帮助
尽管社区已经提供了许多平台的结果,但我仍然对Nehalem旧芯片和Coffee Lake之后新芯片(特别是新的uarch Cannon Lake)的结果感兴趣。 生成这些结果的代码是公开的。 此外,上面的结果也可以在GitHub上以.ods格式获得。
0 特别是,在Skylake中,传统解码器的最大吞吐量显然从4增加到5 uops,uop缓存的最大吞吐量也从4增加到6。这两个因素都可能会影响此处描述的结果。
1 实际上,英特尔喜欢将传统解码器称为MITE(Micro-instruction Translation Engine),可能是因为在架构的任何部分上打上“传统”的标记实际上是一个不当之举。
2 从技术上讲,还有另一种更慢的uops来源-MS(microcode sequencing engine),它用于实现任何具有超过4个uops的指令,但我们在此忽略它,因为我们的循环中没有包含微码指令。
3 这是因为任何对齐的32字节块最多可以使用其uop缓存槽的3路,并且每个槽可容纳多达6个uops。因此,如果在32B块中使用了超过3 * 6 = 18个uops,则根本无法将代码存储在uop缓存中。在实践中很少遇到这种情况,因为代码需要非常紧凑(每个指令少于2个字节)才能触发此条件。
4 nop指令解码为一个uop,但在执行之前不会被消除(即它们不使用执行端口)- 但仍然占用前端空间,因此计入我们感兴趣的各种限制。
5 LSD是循环流检测器,它将最多64个(Skylake)uop的小循环直接缓存到IDQ中。在早期架构中,它可以容纳28个uop(两个逻辑核心活动)或56个uop(一个逻辑核心活动)。
6 我们无法轻松地将2个uop循环放入此模式中,因为这意味着零个nop指令,这意味着dec和jnz指令会宏观融合,并相应地改变uop计数。请相信我,所有具有4个或更少uop的循环最多以1个周期/迭代执行。
7 只是为了好玩,我刚刚在 Firefox 上运行了 perf stat,其中我打开了一个选项卡并在几个 Stack Overflow 问题上点击了一下。对于传递的指令,我从 DSB 获得了46%,从遗留解码器获得了50%,而 LSD 则只有4%。这表明至少对于类似浏览器这样的大型分支代码,DSB 仍然无法捕获大部分代码(幸运的是遗留解码器不太糟糕)。
8 我的意思是,所有其他周期计数都可以通过简单地使用 uops 中的“有效”积分循环成本(可能比实际大小更高)并除以4来解释。对于这些非常短的循环,这种方法行不通-你不能通过将任何整数除以4来达到每迭代1.333个周期。换句话说,在所有其他区域中,成本的形式为某些整数 N 的 N/4。
9实际上,我们知道Skylake可以从传统解码器每个周期交付5个uop,但我们不确定这5个uop是否来自5个不同的指令,还是只有4个或更少。也就是说,我们预计Skylake可以按照2-1-1-1的模式进行解码,但我不确定它是否可以按照1-1-1-1-1的模式进行解码。以上结果表明它确实可以按照1-1-1-1-1的模式进行解码。

perf stat ./a.out给出了来自精确 HW perf 计数器的周期计数。 要正确地进行此操作,您必须知道自己在做什么,但是在此详细级别上已知 x86 微体系结构内部 。 与 ARM 相比,微架构较少。 同一核心设计从 4W Core-M 扩展到 120W 20 核 Xeon,只是具有不同的 uncore / L3。 - Peter Cordes