我正在尝试 Kaggle 房价挑战赛:https://www.kaggle.com/c/house-prices-advanced-regression-techniques。
这是我编写的脚本:
这是我编写的脚本:
train <- read.csv("train.csv")
train$Id <- NULL
previous_na_action = options('na.action')
options(na.action = 'na.pass')
sparse_matrix <- sparse.model.matrix(SalePrice~.-1,data = train)
options(na.action = previous_na_action)
model <- xgboost(data = sparse_matrix, label = train$SalePrice, missing = NA, max.depth = 6, eta = 0.3, nthread = 4, nrounds = 16, verbose = 2, objective = "reg:linear")
importance <- xgb.importance(feature_names = sparse_matrix@Dimnames[[2]], model = model)
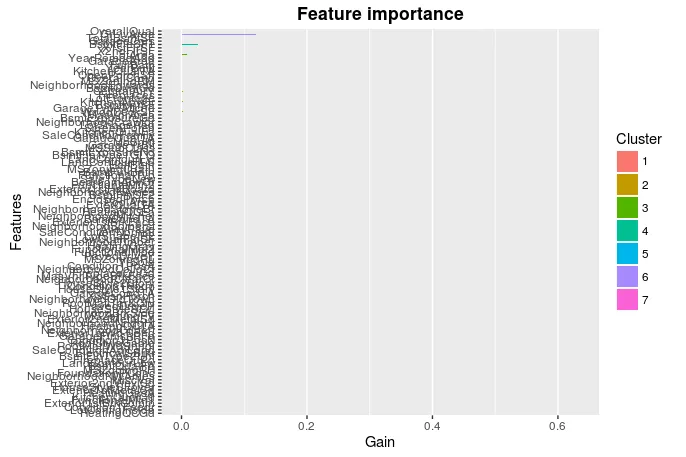
print(xgb.plot.importance(importance_matrix = importance))
数据有超过70个特征,我使用了xgboost,设置max.depth=6和nrounds=16。
我得到的重要性图表非常混乱,我该如何只查看前5个最重要的特征。