一些背景:我有一个n×1的向量e和一个 n×n 的相关矩阵 R。我正在尝试高效地计算在 R 中以下数量的值,而不使用循环: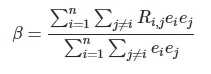 。到目前为止,我已经能够使用单个循环完成,使用以下代码:
。到目前为止,我已经能够使用单个循环完成,使用以下代码:
这样做是可以的,实际上我的计算不会太长,因为对于手头的任务来说,n 的大小最多只有11或12(所以改进可能不会在测量时间性能方面产生很大差异)。然而,我很好奇如何更有效地完成这项工作,因为:
a)R 是对称的,计算只需要使用 R 的主对角线以上(或以下)的部分;
b)我计划将其用于一些大规模的 MC 模拟中,因此任何节省的计算时间都可能对整个计划产生影响。
为了复制/计算目的,这里提供一个可能的数值示例:
。到目前为止,我已经能够使用单个循环完成,使用以下代码:nom <- 0; denom <- 0
for(i in 1:n){
nom <- nom + e[i]*(R[i,-(1:i)]%*%e[-(1:i)])
denom <- denom + e[i]*sum(e[-(1:i)])
}
beta <- nom/denom
这样做是可以的,实际上我的计算不会太长,因为对于手头的任务来说,n 的大小最多只有11或12(所以改进可能不会在测量时间性能方面产生很大差异)。然而,我很好奇如何更有效地完成这项工作,因为:
a)R 是对称的,计算只需要使用 R 的主对角线以上(或以下)的部分;
b)我计划将其用于一些大规模的 MC 模拟中,因此任何节省的计算时间都可能对整个计划产生影响。
为了复制/计算目的,这里提供一个可能的数值示例:
e <- c(0.4972,0.0902,0.02822,0.1688,0.0149,0.0028,0.01411,0.02733,0.0151,0.0391,0.01301,0.0894)
R <- matrix(data = c(1,0.9,0.4,0.75,0.5,0.3,0.4,0.4,0.25,0.25,0.5,0.4,0.9,1,0.5,0.9,0.5,0.3,0.4,0.35,0.2,0.2,0.5,0.3,0.4,0.5,1,0.3,0.5,0.4,0.25,0.2,0.2,0.2,0.3,0.3,0.75,0.9,0.3,1,0.3,0.3,0.4,0.25,0.25,0.2,0.3,0.75,0.5,0.5,0.5,0.3,1,0.5,0.35,0.8,0.8,0.3,0.7,0.45,0.3,0.3,0.4,0.3,0.5,1,0.3,0.4,0.3,0.2,0.45,0.35,0.4,0.4,0.25,0.4,0.35,0.3,1,0.3,0.3,0.2,0.5,0.5,0.4,0.35,0.2,0.25,0.8,0.4,0.3,1,0.8,0.2,0.6,0.8,0.25,0.2,0.2,0.25,0.8,0.3,0.3,0.8,1,0.3,0.7,0.8,0.25,0.2,0.2,0.2,0.3,0.2,0.2,0.2,0.3,1,0.25,0.3,0.5,0.5,0.3,0.3,0.7,0.45,0.5,0.6,0.7,0.25,1,0.7,0.4,0.3,0.3,0.75,0.45,0.35,0.5,0.8,0.8,0.3,0.7,1), nrow = 12, ncol = 12)