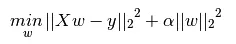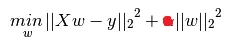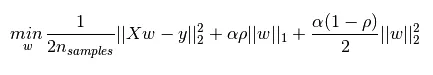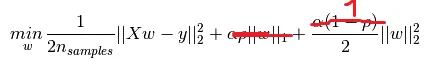弹性网络被认为是岭回归(L2正则化)和套索(L1正则化)之间的混合体。然而,即使l1_ratio为0,我得到的结果也不同于岭回归。我知道岭回归使用梯度下降,而弹性网络使用坐标下降,但最优解应该是相同的,不是吗?此外,我发现弹性网络经常无明显原因地出现收敛警告,而lasso和ridge则没有。以下是代码片段:
from sklearn.datasets import load_boston
from sklearn.utils import shuffle
from sklearn.linear_model import ElasticNet, Ridge, Lasso
from sklearn.model_selection import train_test_split
data = load_boston()
X, y = shuffle(data.data, data.target, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=43)
alpha = 1
en = ElasticNet(alpha=alpha, l1_ratio=0)
en.fit(X_train, y_train)
print('en train score: ', en.score(X_train, y_train))
rr = Ridge(alpha=alpha)
rr.fit(X_train, y_train)
print('rr train score: ', rr.score(X_train, y_train))
lr = Lasso(alpha=alpha)
lr.fit(X_train, y_train)
print('lr train score: ', lr.score(X_train, y_train))
print('---')
print('en test score: ', en.score(X_test, y_test))
print('rr test score: ', rr.score(X_test, y_test))
print('lr test score: ', lr.score(X_test, y_test))
print('---')
print('en coef: ', en.coef_)
print('rr coef: ', rr.coef_)
print('lr coef: ', lr.coef_)
即使l1_ratio为0,弹性网的训练和测试得分也接近套索得分(而不是岭回归得分,这可能出乎你的意料)。此外,弹性网似乎会抛出一个ConvergenceWarning警告,即使我增加max_iter(甚至增加到1000000也没有效果)和tol(0.1仍然会出错,但0.2不会)。增加alpha(如警告建议)也没有效果。