我正在参加编程比赛,其中我有一些数据,第一列是用户,第二列是电影,第三列是十分制评分系统中的数字。
0 0 9
0 1 8
1 1 4
1 2 6
2 2 7
我需要预测第三列(用户,电影,?):
0 2
1 0
2 0
2 1
此外,我知道答案:
0 2 7.052009
1 0 6.687943
2 0 6.995272
2 1 6.687943
这是一个表格数据:行代表用户0、1和2;列代表电影0、1和2;单元格中的数字表示得分,
0表示未投票: [,1] [,2] [,3]
[1,] 9 8 0
[2,] 0 4 6
[3,] 0 0 7
我使用R语言进行奇异值分解(SVD):
$d
[1] 12.514311 9.197763 2.189331
$u
[,1] [,2] [,3]
[1,] 0.9318434 -0.3240669 0.1632436
[2,] 0.3380257 0.6116879 -0.7152458
[3,] 0.1319333 0.7216776 0.6795403
$v
[,1] [,2] [,3]
[1,] 0.6701600 -0.31709904 0.6710691
[2,] 0.7037423 -0.01584988 -0.7102785
[3,] 0.2358650 0.94825998 0.2125341
转置后的v是:
[,1] [,2] [,3]
[1,] 0.6701600 0.7037423 0.2358650
[2,] -0.31709904 -0.01584988 0.94825998
[3,] 0.6710691 -0.7102785 0.2125341
我了解到可以使用以下公式来预测电影评分:
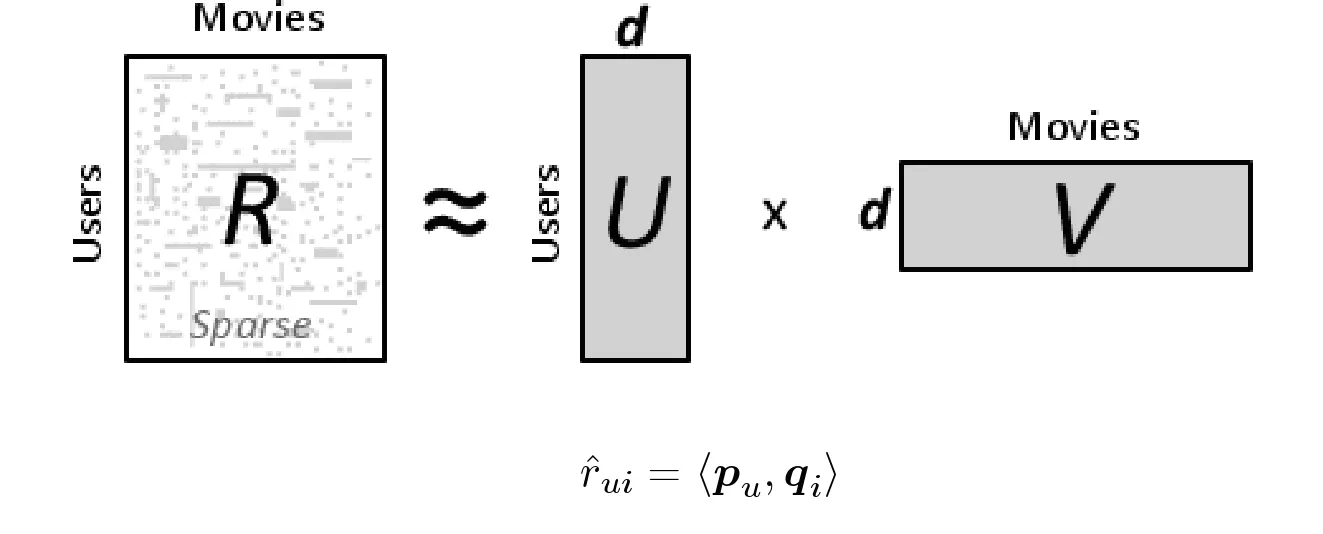
但我不明白如何用这种方式来预测评分:
0 2 7.052009
1 0 6.687943
2 0 6.995272
2 1 6.687943
对于这个数据:
0 2
1 0
2 0
2 1