我有一个txt文件,想要使用pandas读取它,
感谢@jezrael的回答。在我删除了顶部所有无用信息之后,它起作用了。有没有不编辑原始文件就能做到这一点的方法?
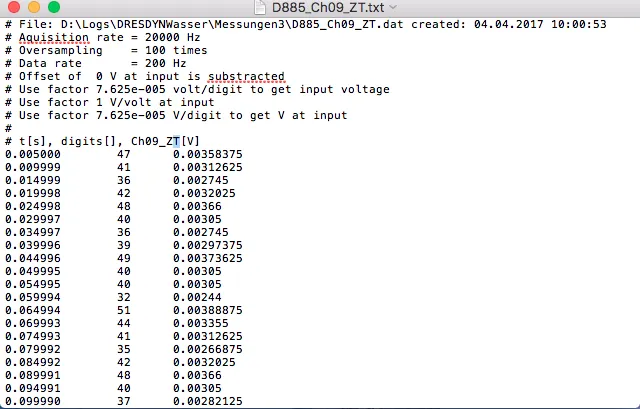
我写道:
#!/usr/bin/python
import pandas as pd
import numpy as np
TC=pd.read_csv('D885_Ch10_ZC.csv',error_bad_lines=False,encoding='gbk')
df=pd.DataFrame(TC,columns=['t[s]','digits[]','Ch10_zc[V]'])
print(df)
我发现数据被替换为NaN,但我不知道原因。
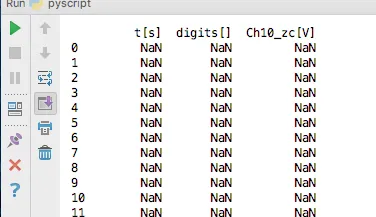
感谢@jezrael的回答。在我删除了顶部所有无用信息之后,它起作用了。有没有不编辑原始文件就能做到这一点的方法?