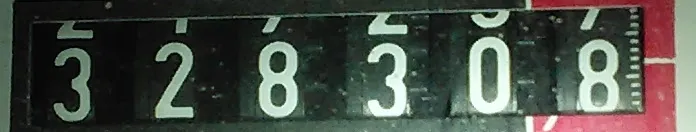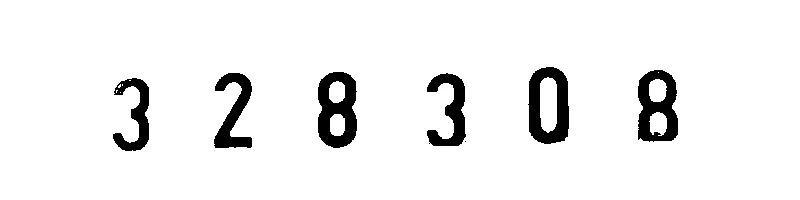我正在开发一款可以识别车牌(ANPR)的应用程序。第一步是从图像中提取车牌。我使用OpenCV根据宽高比来检测车牌,效果还不错:


但是,正如你所看到的,OCR的结果非常糟糕。
在我的Objective C(iOS)环境中,我使用tesseract。这些是启动引擎时的init变量:
// init the tesseract engine.
tesseract = new tesseract::TessBaseAPI();
int initRet=tesseract->Init([dataPath cStringUsingEncoding:NSUTF8StringEncoding], [language UTF8String]);
tesseract->SetVariable("tessedit_char_whitelist", "BCDFGHJKLMNPQRSTVWXYZ0123456789-");
tesseract->SetVariable("language_model_penalty_non_freq_dict_word", "1");
tesseract->SetVariable("language_model_penalty_non_dict_word ", "1");
tesseract->SetVariable("load_system_dawg", "0");
我该如何改善结果?我需要让OpenCV做更多的图像处理吗?还是我可以通过tesseract来改进一些东西?