我正在使用tesseract识别序列号。这个工具可以正常工作,但是存在一些常见问题,例如零和“O”,6和5,或M和H的误识别。
除此之外,tesseract会在识别出的单词中添加空格,而图像中并没有空格。以下图像被识别为"HI 3H"。

这张图片的结果是" FBKHJ 1R1"
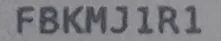
因此,即使图像中实际上没有空格,tesseract也会添加一个空格。有没有可能参数化tesseract的间距行为呢?
编辑
很抱歉,我忘记了补充一点,我还有包含空格的序列号。所以我不能删除识别出的序列号中的所有空格。
例如,下面这张包含空格的图像,在经过tesseract识别后变成了J4 F1583BB。除了字符识别错误之外,这张图片的空格被正确识别了。
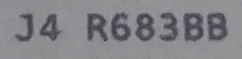
我目前使用的tesseract参数是:
tesseract::TessBaseAPI tess;
tess.Init(NULL, "eng", tesseract::OEM_TESSERACT_ONLY);
tess.SetPageSegMode(tesseract::PSM_SINGLE_BLOCK);
tess.SetVariable("tessedit_char_whitelist",
"ABCDEFGHIJKLMNOPQRSTUVWXYZ012345789");
char* out = tess.GetUTF8Text();
string text = string(out);
编辑
从已有的答案中可以看出,例如字母“J”和“I”之间的空格似乎比其他字符之间的空格稍微大一些。我选择的字体类型是等宽字体。这样做的原因是我认为这有助于Tesseract进行字符识别。这种等宽字体的缺点是内核(字符之间的空间)会有所变化。请参见以下来源的示例图像Source

你认为哪种字体类型能够实现更好的识别结果?
TessBaseAPI对象上调用Init时,将"eng"作为第二个参数传递。这是用来指定字符集还是语言?如果是后者,您能否更改为一个选项,只涉及字母数字字符,但没有英语的语义? - Sam EstepFBK中,J 和 I 之间的距离可能是一个空格,即使对于人类来说也是如此。 - UmNyobetextord/tospace.cpp,如https://groups.google.com/forum/#!msg/tesseract-ocr/PepNaRySaHw/XzmKb_yZ7mkJ所建议的那样(都可以在谷歌上找到)。 - Micka