编辑
我找到了一个非常好的解决方案,并在下面作为答案发布。 结果看起来像这样:
您可以生成一些用于此问题的示例数据:
codes = list('ABCDEFGH');
dates = pd.Series(pd.date_range('2013-11-01', '2014-01-31'));
dates = dates.append(dates)
dates.sort()
df = pd.DataFrame({'amount': np.random.randint(1, 10, dates.size), 'col1': np.random.choice(codes, dates.size), 'col2': np.random.choice(codes, dates.size), 'date': dates})
导致:
In [55]: df
Out[55]:
amount col1 col2 date
0 1 D E 2013-11-01
0 5 E B 2013-11-01
1 5 G A 2013-11-02
1 7 D H 2013-11-02
2 5 E G 2013-11-03
2 4 H G 2013-11-03
3 7 A F 2013-11-04
3 3 A A 2013-11-04
4 1 E G 2013-11-05
4 7 D C 2013-11-05
5 5 C A 2013-11-06
5 7 H F 2013-11-06
6 1 G B 2013-11-07
6 8 D A 2013-11-07
7 1 B H 2013-11-08
7 8 F H 2013-11-08
8 3 A E 2013-11-09
8 1 H D 2013-11-09
9 3 B D 2013-11-10
9 1 H G 2013-11-10
10 6 E E 2013-11-11
10 6 F E 2013-11-11
11 2 G B 2013-11-12
11 5 H H 2013-11-12
12 5 F G 2013-11-13
12 5 G B 2013-11-13
13 8 H B 2013-11-14
13 6 G F 2013-11-14
14 9 F C 2013-11-15
14 4 H A 2013-11-15
.. ... ... ... ...
77 9 A B 2014-01-17
77 7 E B 2014-01-17
78 4 F E 2014-01-18
78 6 B E 2014-01-18
79 6 A H 2014-01-19
79 3 G D 2014-01-19
80 7 E E 2014-01-20
80 6 G C 2014-01-20
81 9 H G 2014-01-21
81 9 C B 2014-01-21
82 2 D D 2014-01-22
82 7 D A 2014-01-22
83 6 G B 2014-01-23
83 1 A G 2014-01-23
84 9 B D 2014-01-24
84 7 G D 2014-01-24
85 7 A F 2014-01-25
85 9 B H 2014-01-25
86 9 C D 2014-01-26
86 5 E B 2014-01-26
87 3 C H 2014-01-27
87 7 F D 2014-01-27
88 3 D G 2014-01-28
88 4 A D 2014-01-28
89 2 F A 2014-01-29
89 8 D A 2014-01-29
90 1 A G 2014-01-30
90 6 C A 2014-01-30
91 6 H C 2014-01-31
91 2 G F 2014-01-31
[184 rows x 4 columns]
我希望您可以按照日历周和
col1的值进行分组。就像这样:kw = lambda x: x.isocalendar()[1]
grouped = df.groupby([df['date'].map(kw), 'col1'], sort=False).agg({'amount': 'sum'})
导致:
In [58]: grouped
Out[58]:
amount
date col1
44 D 8
E 10
G 5
H 4
45 D 15
E 1
G 1
H 9
A 13
C 5
B 4
F 8
46 E 7
G 13
H 17
B 9
F 23
47 G 14
H 4
A 40
C 7
B 16
F 13
48 D 7
E 16
G 9
H 2
A 7
C 7
B 2
... ...
1 H 14
A 14
B 15
F 19
2 D 13
H 13
A 13
B 10
F 32
3 D 8
E 18
G 3
H 6
A 30
C 9
B 6
F 5
4 D 9
E 12
G 19
H 9
A 8
C 18
B 18
5 D 11
G 2
H 6
A 5
C 9
F 9
[87 rows x 1 columns]
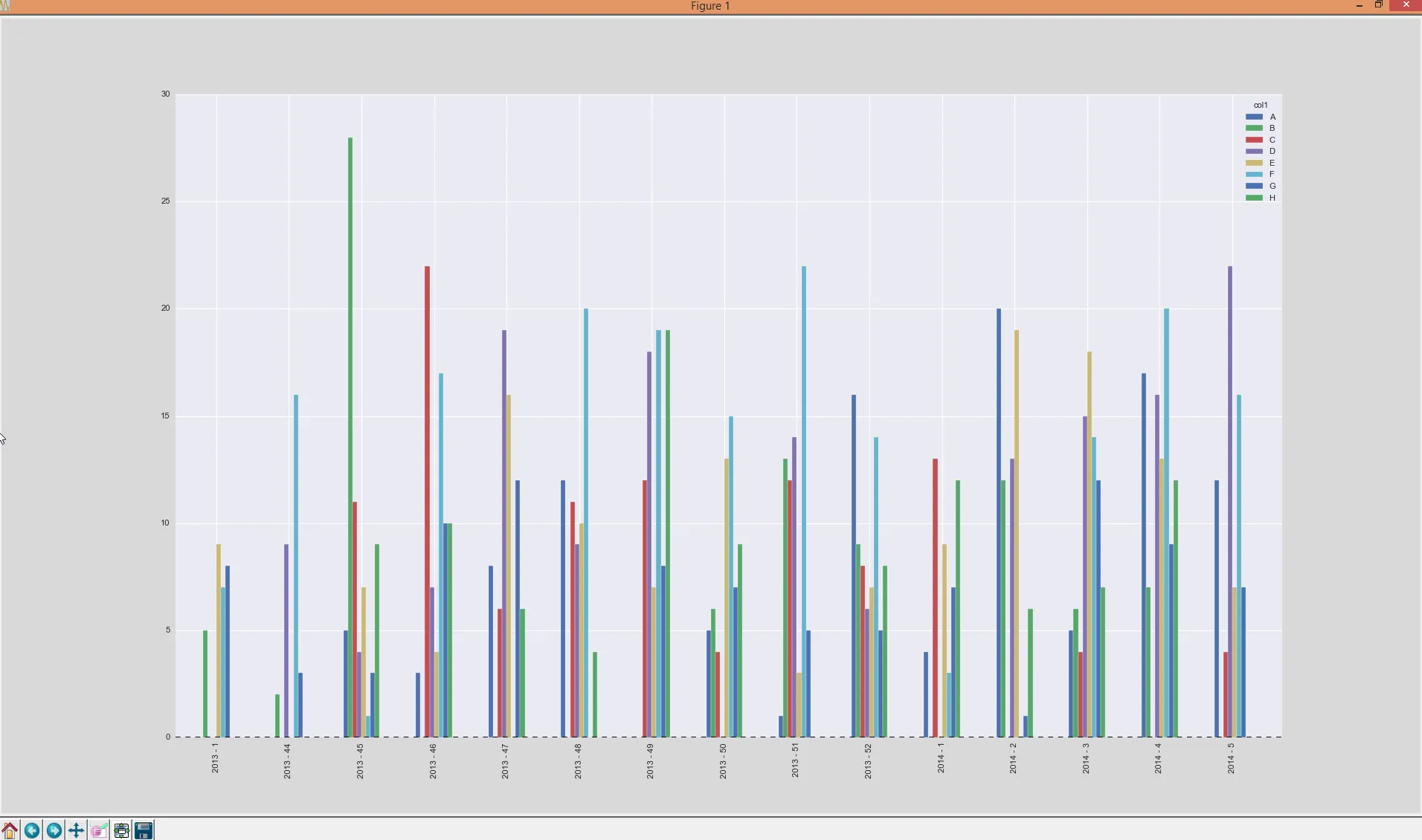
我希望生成像这样的绘图:
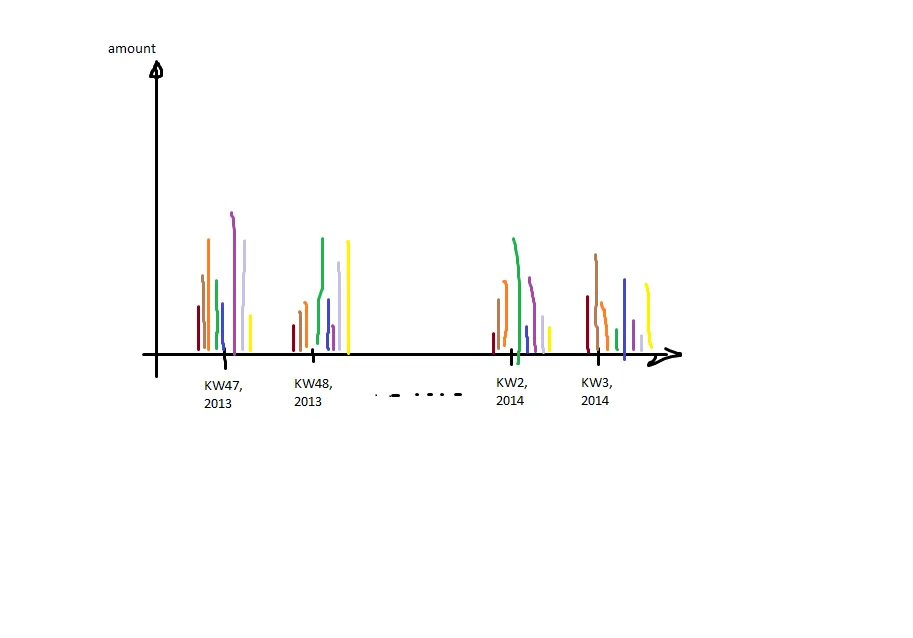 这意味着:在x轴上是日历周和年份(日期时间),对于每个分组的
这意味着:在x轴上是日历周和年份(日期时间),对于每个分组的col1,都有一个条形图。我面临的问题是:我只有描述日历周(KW)的整数,但我必须以此合并日期以便得到由年份标记的刻度。此外,我不能仅绘制分组的日历周,因为我需要正确排列项目的顺序(KW 47,KW 48(2013年)必须位于 KW 1 的左侧(因为这是2014年))。
编辑
从这里我找到了解决方法:http://pandas.pydata.org/pandas-docs/stable/visualization.html#visualization-barplot 分组条形图需要是列而不是行。 所以我想如何转换数据,并找到了一个很好的函数 pivot。需要使用 reset_index将多级索引转换为列。最后,用零填充 NaN:
A = grouped.reset_index().pivot(index='date', columns='col1', values='amount').fillna(0)
将数据转换为:
col1 A B C D E F G H
date
1 4 31 0 0 0 18 13 8
2 0 12 13 22 1 17 0 8
3 3 10 4 13 12 8 7 6
4 17 0 10 7 0 25 7 4
5 7 0 7 9 8 6 0 7
44 0 0 2 11 7 0 0 2
45 9 3 2 14 0 16 21 2
46 0 14 7 2 17 13 11 8
47 5 13 0 15 19 7 5 10
48 15 8 12 2 20 4 7 6
49 20 0 0 18 22 17 11 0
50 7 11 8 6 5 6 13 10
51 8 26 0 0 5 5 16 9
52 8 13 7 5 4 10 0 11
这看起来像文档中的示例数据,可以用于绘制分组条形图:
A. plot(kind='bar')
如下图所示:
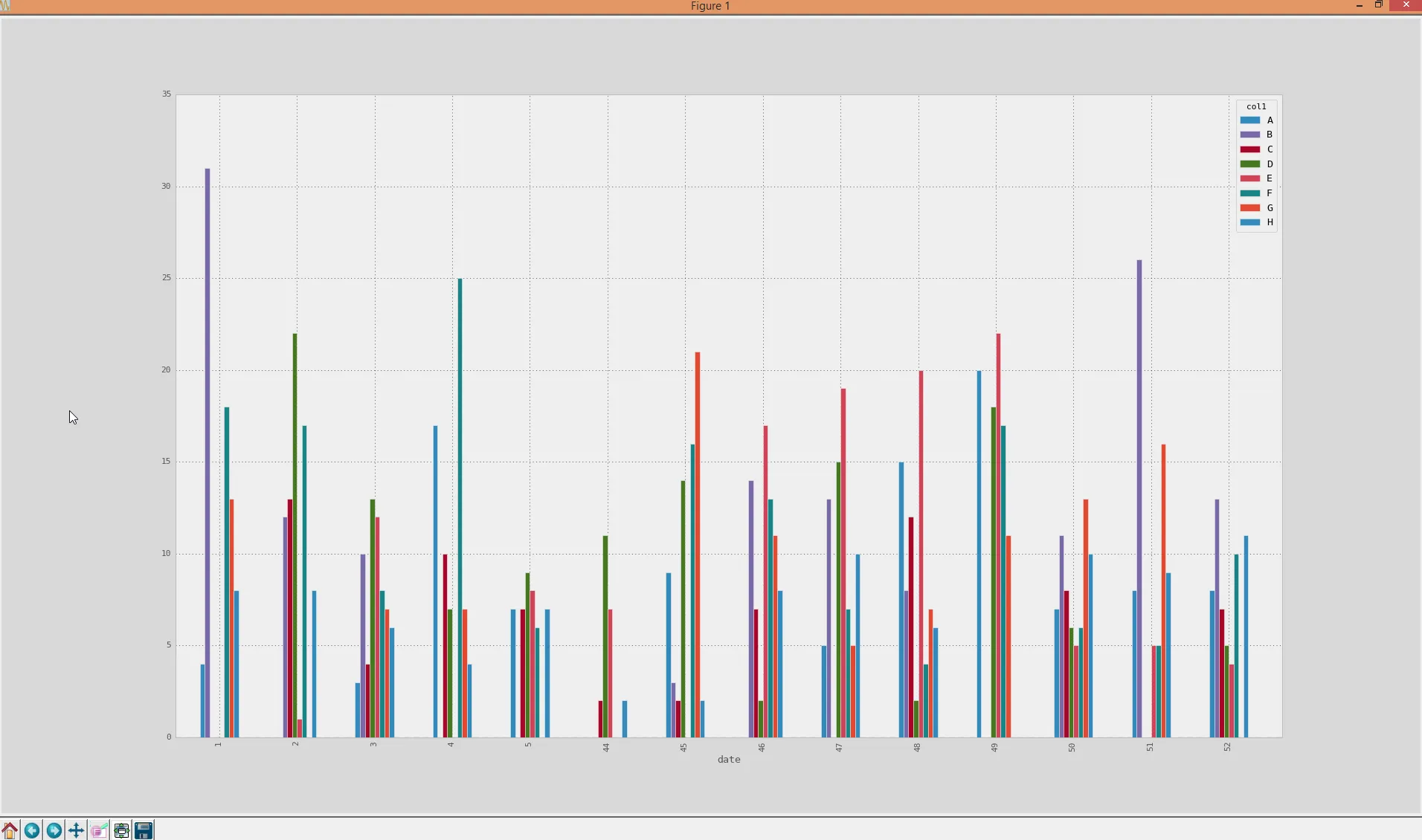
我的问题是轴按照当前排序(从1到52),这实际上是错误的,因为在这种情况下,第52周属于2013年... 有什么想法可以将真实日期时间合并回来作为x轴刻度?