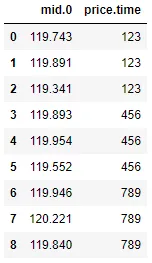
我想要做的是通过Pandas加载外汇历史价格数据的json文件,并对该数据进行统计分析。我已经阅读了许多关于Pandas和解析json文件的主题。我希望将具有额外值和嵌套列表的json文件传递给pandas dataframe。
我获得了一个json文件'EUR_JPY_H8.json'
首先我导入所需的库,
import pandas as pd
import json
from pandas.io.json import json_normalize
然后加载json文件,
with open('EUR_JPY_H8.json') as data_file:
data = json.load(data_file)
我有以下列表:
[{u'complete': True,
u'mid': {u'c': u'119.743',
u'h': u'119.891',
u'l': u'119.249',
u'o': u'119.341'},
u'time': u'1488319200.000000000',
u'volume': 14651},
{u'complete': True,
u'mid': {u'c': u'119.893',
u'h': u'119.954',
u'l': u'119.552',
u'o': u'119.738'},
u'time': u'1488348000.000000000',
u'volume': 10738},
{u'complete': True,
u'mid': {u'c': u'119.946',
u'h': u'120.221',
u'l': u'119.840',
u'o': u'119.888'},
u'time': u'1488376800.000000000',
u'volume': 10041}]
然后我将列表传递给json_normalize。尝试获取在'mid'下的嵌套列表中的价格。
result = json_normalize(data,'time',['time','volume','complete',['mid','h'],['mid','l'],['mid','c'],['mid','o']])
但我的结果是这样的:
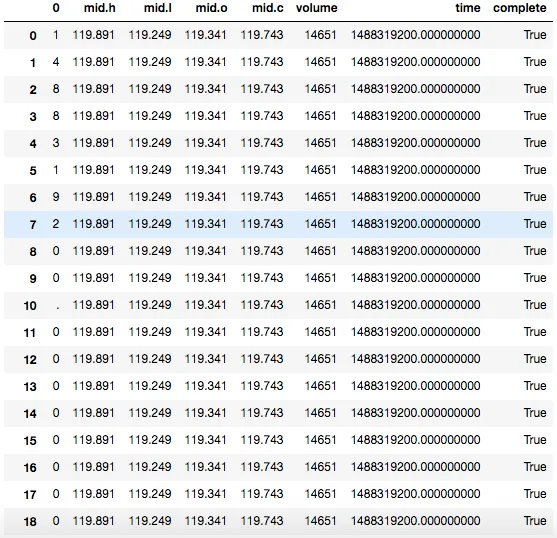
时间数据被拆分成了每一行的整数。
我查看了相关文档。我必须将字符串或列表对象传递给json_normalize的第二个参数。如何在不拆分时间戳的情况下传递它?
我期望输出的列为:
index | time | volumn | completed | mid.h | mid.l | mid.c | mid.o