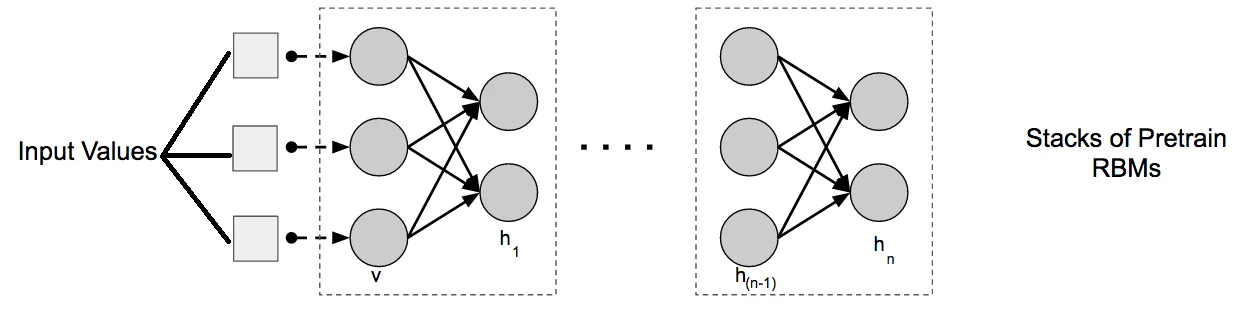
根据这个网站,深度置信网络只是将多个RBM堆叠在一起,使用前一个RBM的输出作为下一个RBM的输入。
 在scikit-learn文档中,有一个使用RBM对MNIST数据集进行分类的示例。他们将
在scikit-learn文档中,有一个使用RBM对MNIST数据集进行分类的示例。他们将
因此,我想知道是否可以将多个RBM添加到该管道中,以创建如下代码所示的深度置信网络。
然而,我发现在管道中添加更多的RBM会降低准确性。
在scikit-learn文档中,有一个使用RBM对MNIST数据集进行分类的示例。他们将RBM和LogisticRegression放在管道中以获得更好的准确性。因此,我想知道是否可以将多个RBM添加到该管道中,以创建如下代码所示的深度置信网络。
from sklearn.neural_network import BernoulliRBM
import numpy as np
from sklearn import linear_model, datasets, metrics
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
digits = datasets.load_digits()
X = np.asarray(digits.data, 'float32')
Y = digits.target
X = (X - np.min(X, 0)) / (np.max(X, 0) + 0.0001) # 0-1 scaling
X_train, X_test, Y_train, Y_test = train_test_split(X, Y,
test_size=0.2,
random_state=0)
logistic = linear_model.LogisticRegression(C=100)
rbm1 = BernoulliRBM(n_components=100, learning_rate=0.06, n_iter=100, verbose=1, random_state=101)
rbm2 = BernoulliRBM(n_components=80, learning_rate=0.06, n_iter=100, verbose=1, random_state=101)
rbm3 = BernoulliRBM(n_components=60, learning_rate=0.06, n_iter=100, verbose=1, random_state=101)
DBN3 = Pipeline(steps=[('rbm1', rbm1),('rbm2', rbm2), ('rbm3', rbm3), ('logistic', logistic)])
DBN3.fit(X_train, Y_train)
print("Logistic regression using RBM features:\n%s\n" % (
metrics.classification_report(
Y_test,
DBN3.predict(X_test))))
然而,我发现在管道中添加更多的RBM会降低准确性。
1个RBM在管道中--> 95%
2个RBM在管道中--> 93%
3个RBM在管道中--> 89%
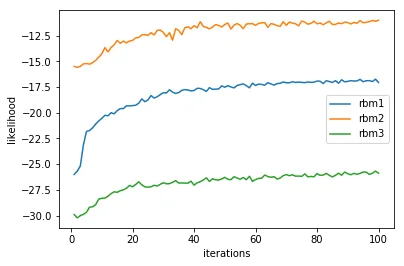
下面的训练曲线显示,100次迭代是收敛的最佳选择。过多的迭代会导致过拟合,可能性再次降低。
批处理大小=10
批次大小为256或更高
我注意到一件有趣的事情。如果我使用更高的批量大小,网络的性能会大大恶化。当批量大小超过256时,准确度下降到不到10%。对我来说,训练曲线似乎没有意义,第一和第二个RBM学习不多,但第三个RBM突然学得很快。
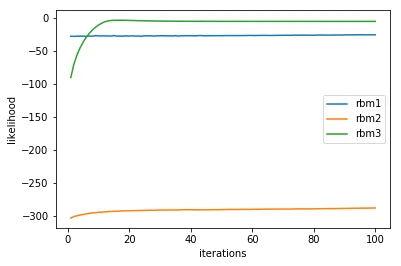
看起来89%是具有3个RBM的网络的瓶颈。
我想知道我是否做错了什么。我的深度置信网络理解正确吗?