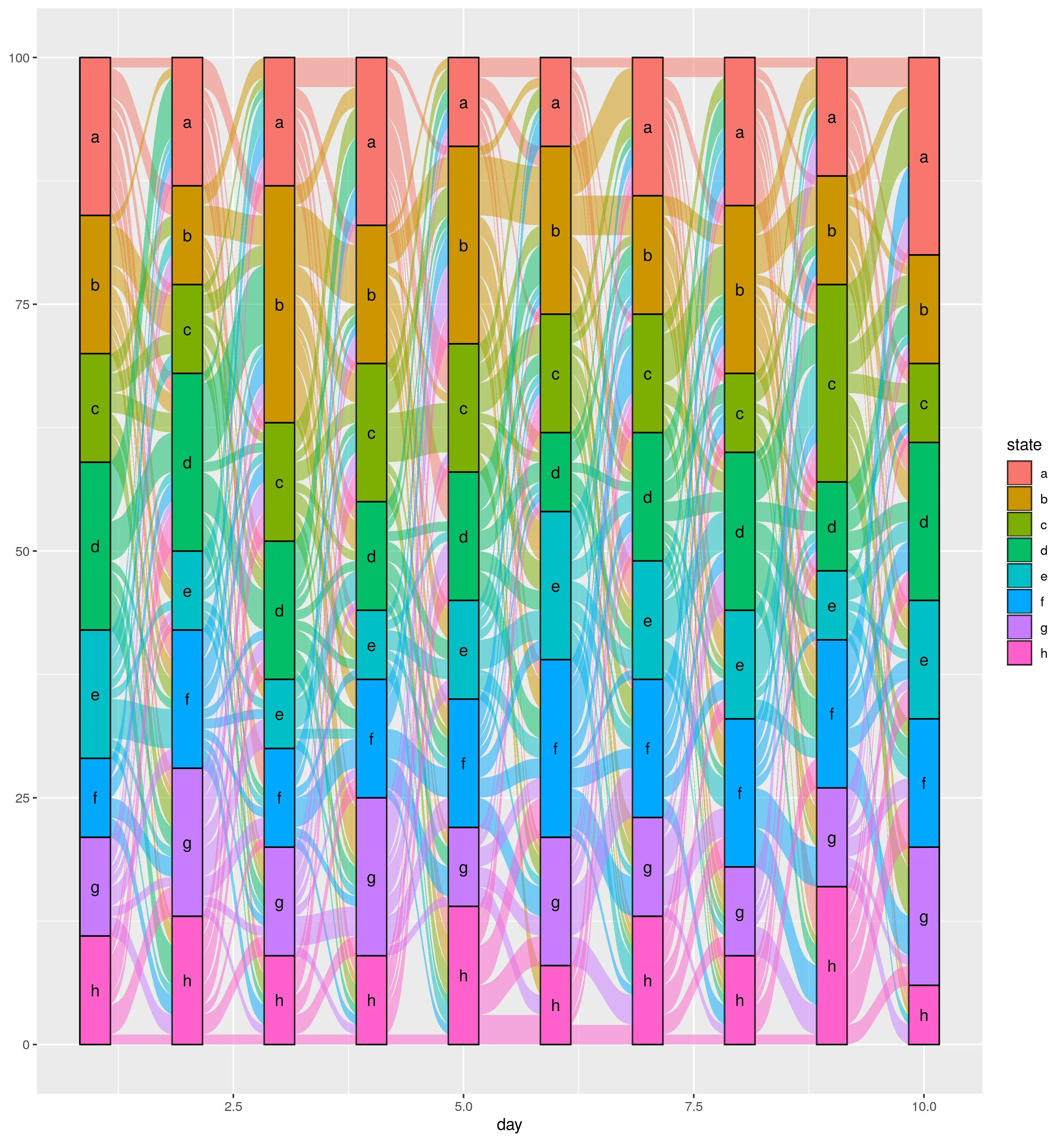
我正在尝试在R中生成桑基图,也称为河流图。我看到了这个问题在R中制作桑基图?,其中列出了许多可以生成桑基图的软件包。由于我已经有了输入数据并知道不同的工具/软件包,我可以生成这样的图表,但我的问题是:如何准备输入数据呢?
假设我们想展示用户在10天内如何在各个状态之间迁移,并且有以下起始数据集:
现在,如果想使用
这样我们就可以得到像这个例子中的输入。
假设我们想展示用户在10天内如何在各个状态之间迁移,并且有以下起始数据集:
data.frame(userID = 1:100,
day1_state = sample(letters[1:8], replace = TRUE, size = 100),
day2_state = sample(letters[1:8], replace = TRUE, size = 100),
day3_state = sample(letters[1:8], replace = TRUE, size = 100),
day4_state = sample(letters[1:8], replace = TRUE, size = 100),
day5_state = sample(letters[1:8], replace = TRUE, size = 100),
day6_state = sample(letters[1:8], replace = TRUE, size = 100),
day7_state = sample(letters[1:8], replace = TRUE, size = 100),
day8_state = sample(letters[1:8], replace = TRUE, size = 100),
day9_state = sample(letters[1:8], replace = TRUE, size = 100),
day10_state = sample(letters[1:8], replace = TRUE, size = 100)
) -> dt
现在,如果想使用
networkD3包创建桑基图,应该如何将这个dt数据框转换为所需的输入格式?这样我们就可以得到像这个例子中的输入。
library(networkD3)
URL <- paste0(
"https://cdn.rawgit.com/christophergandrud/networkD3/",
"master/JSONdata/energy.json")
Energy <- jsonlite::fromJSON(URL)
# Plot
sankeyNetwork(Links = Energy$links, Nodes = Energy$nodes, Source = "source",
Target = "target", Value = "value", NodeID = "name",
units = "TWh", fontSize = 12, nodeWidth = 30)
编辑
我找到了一段脚本,可以在其他情况下准备数据,并复制了它,所以我认为现在可能已经关闭了:
https://github.com/mi2-warsaw/JakOniGlosowali/blob/master/sankey/sankey.R