我想知道是否有可能改变数据框的列位置,实际上是改变模式(schema)呢?
具体来说,如果我有一个类似于 [field1, field2, field3] 的数据框,而我想要得到的是 [field1, field3, field2]。
我无法提供任何代码片段。假设我们正在使用一个包含一百个列的数据框,在进行一些连接和转换之后,其中的一些列相对于目标表的架构是错位的。
如何移动一个或多个列,即如何更改模式?
我想知道是否有可能改变数据框的列位置,实际上是改变模式(schema)呢?
具体来说,如果我有一个类似于 [field1, field2, field3] 的数据框,而我想要得到的是 [field1, field3, field2]。
我无法提供任何代码片段。假设我们正在使用一个包含一百个列的数据框,在进行一些连接和转换之后,其中的一些列相对于目标表的架构是错位的。
如何移动一个或多个列,即如何更改模式?
您可以获取列名称,按照自己的需要重新排序,然后在原始DataFrame上使用select来获取一个新的DataFrame,其顺序为这个新顺序:
val columns: Array[String] = dataFrame.columns
val reorderedColumnNames: Array[String] = ??? // do the reordering you want
val result: DataFrame = dataFrame.select(reorderedColumnNames.head, reorderedColumnNames.tail: _*)
.tail: _* 部分。我发现即使在Java中创建字符串数组也很困难。 - soMuchToLearnAndSharedataFrame.select(reorderedColumnNames[0], Arrays.copyOfRange(reorderedColumnNames, 1, reorderedColumnNames.length)。完整的文档可参见https://spark.apache.org/docs/1.6.1/api/java/org/apache/spark/sql/DataFrame.html#select(java.lang.String,%20java.lang.String...)。 - Tzach Zoharspark-daria库提供了一个reorderColumns方法,可以轻松地重新排列DataFrame中的列。
import com.github.mrpowers.spark.daria.sql.DataFrameExt._
val actualDF = sourceDF.reorderColumns(
Seq("field1", "field3", "field2")
)
reorderColumns 方法在实现时使用了 @Rockie Yang 的解决方案。
如果你想让 df1 的列顺序与 df2 相同,以下方法比硬编码所有列更有效:
df1.reorderColumns(df2.columns)
spark-daria库还定义了一个sortColumns变换,用于按升序或降序排序列(如果您不想在顺序中指定所有列)。
import com.github.mrpowers.spark.daria.sql.transformations._
df.transform(sortColumns("asc"))
像其他人评论的一样,我很好奇为什么要这样做,因为当您可以通过列名查询列时,顺序并不重要。
无论如何,使用select应该会让列在模式描述中移动的感觉:
val data = Seq(
("a", "hello", 1),
("b", "spark", 2)
)
.toDF("field1", "field2", "field3")
data
.show()
data
.select("field3", "field2", "field1")
.show()
val cols = df.columns.map(df(_)).reverse
val reversedColDF = df.select(cols:_*)
对于任何动态框架,首先将其转换为数据框架以使用标准的pyspark函数。
data_frame = dynamic_frame.toDF()
现在,使用 select 函数操作,将列重新排列到新的数据框中。
data_frame_temp = data_frame.select(["col_5","col_1","col_2","col_3","col_4"])
Spark Scala示例:
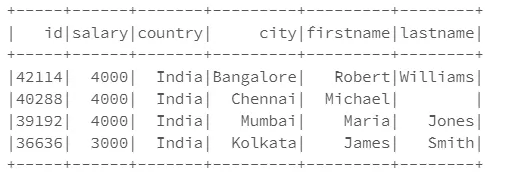
假设您有一个名为demo_df的数据框,并且它具有以下列集:
id, salary, country, city, firstname, lastname
您想要重新排列其顺序。
demo_df
选择所有列并删除您要重新排列的列。
我从列列表中删除了“salary,country,city”列。
val restcols = demo_df.columns.diff(Seq("salary", "country", "city"))
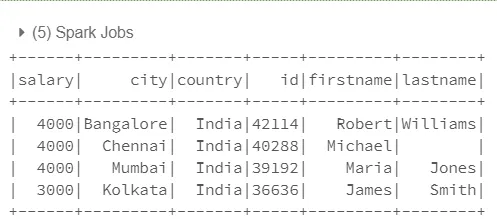
现在根据您的要求重新排列列名并将其附加或前置到剩余的列中
在列(s)前面添加的示例
val all_cols = Seq($"salary", $"city", $"country") ++: restcols.map(col(_))
现在选择数据框并提供新定义的列列表
demo_df.select(all_cols: _*).show()
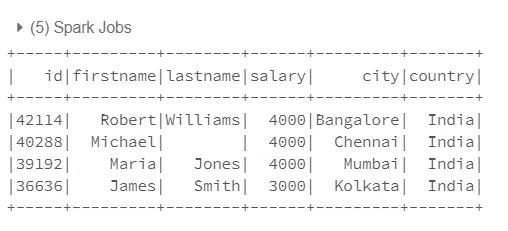
在列(s)后面添加的示例
val all_cols = restcols.map(col(_)) ++ Seq($"salary", $"city", $"country")
demo_df.select(all_cols: _*).show()
希望能有所帮助。 快乐编码!
以下是pyspark中的操作:
与MySQL查询类似,您可以重新选择所需的列顺序并将其传递给参数,返回与查询参数相同的顺序。
from pyspark.sql import SparkSession
data = [
{'id': 1, 'sex': 1, 'name': 'foo', 'age': 13},
{'id': 1, 'sex': 0, 'name': 'bar', 'age': 12},
]
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.getOrCreate()
# init df
df = spark.createDataFrame(data)
df.show()
+---+---+----+---+
|age| id|name|sex|
+---+---+----+---+
| 13| 1| foo| 1|
| 12| 1| bar| 0|
+---+---+----+---+
将您想要的列位置顺序作为参数传递给select
# change columns position
df = df.select(df.id, df.name, df.age, df.sex)
df.show()
+---+----+---+---+
| id|name|age|sex|
+---+----+---+---+
| 1| foo| 13| 1|
| 1| bar| 12| 0|
+---+----+---+---+
我希望能为您提供帮助。
df.write.insertInto(table)的行为类似于 SQL 插入语句,通过位置而不是名称将数据框列与输出 SQL 列进行匹配。 - blue