我知道使用适当的函数结构编写没有任何问题,但我想知道如何使用一行代码以最Pythonic的方式找到第n个斐波那契数。
我写了那段代码,但是它似乎不是最好的方式:
>>> fib = lambda n:reduce(lambda x, y: (x[0]+x[1], x[0]), [(1,1)]*(n-2))[0]
>>> fib(8)
13
如何让它更好、更简单?
fib = lambda n:reduce(lambda x,n:[x[1],x[0]+x[1]], range(n),[0,1])[0]
(这会维护一个从 [a,b] 映射到 [b,a+b] 的元组,初始值为 [0,1],迭代 N 次后取第一个元素)
>>> fib(1000)
43466557686937456435688527675040625802564660517371780402481729089536555417949051
89040387984007925516929592259308032263477520968962323987332247116164299644090653
3187938298969649928516003704476137795166849228875L
(请注意,在这个编号中,fib(0) = 0,fib(1) = 1,fib(2) = 1,fib(3) = 2,依此类推。)
(同时注意:在Python 2.7中,reduce是内置函数,但在Python 3中不是;您需要在Python 3中执行from functools import reduce。)
reduce 函数的输入函数接受两个参数:累加器和输入。对于可迭代对象中的每个元素(在本例中是 range(n)),reduce 都会调用该函数。在这种情况下,累加器是一个元组 x,初始化为 [0,1]。reduce() 函数中的函数输出一个新的元组 [x[1],x[0]+x[1]]。 - Jason S一个很少见的技巧是lambda函数可以递归地引用自身:
fib = lambda n: n if n < 2 else fib(n-1) + fib(n-2)
顺便说一下,这种写法很少见,因为它容易让人困惑,而且在这种情况下也不太高效。最好还是将其分行书写:
def fibs():
a = 0
b = 1
while True:
yield a
a, b = b, a + b
fib = lambda n,m={}: m.get(n) or m.setdefault(n, n if n < 2 else fib(n - 1) + fib(n - 2)) - John La Rooy最近我学到了使用矩阵乘法生成斐波那契数列,感觉很酷。你需要一个基础矩阵:
[1, 1]
[1, 0]
并将其自乘N次,得到:
[F(N+1), F(N)]
[F(N), F(N-1)]
import numpy
def mm_fib(n):
return (numpy.matrix([[2,1],[1,1]])**(n//2))[0,(n+1)%2]
>>> [mm_fib(i) for i in range(20)]
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181]
这是一个使用整数算术的斐波那契数列的封闭表达式,非常高效。
fib = lambda n:pow(2<<n,n+1,(4<<2*n)-(2<<n)-1)%(2<<n)
>> fib(1000)
4346655768693745643568852767504062580256466051737178
0402481729089536555417949051890403879840079255169295
9225930803226347752096896232398733224711616429964409
06533187938298969649928516003704476137795166849228875L
它在O(log n)的算术运算中计算结果,每个操作都作用于O(n)位的整数。考虑到结果(第n个斐波那契数)是O(n)位,该方法相当合理。
它基于http://fare.tunes.org/files/fun/fibonacci.lisp中的genefib4,而该文件又基于我不那么高效的闭式整数表达式(请参见:http://paulhankin.github.io/Fibonacci/)。
如果我们认为“最Pythonic的方式”是优雅而有效的,那么:
def fib(nr):
return int(((1 + math.sqrt(5)) / 2) ** nr / math.sqrt(5) + 0.5)
wins hands down. 为什么要使用低效的算法(即使你开始使用记忆化,我们也可以忘记这个一行代码的解决方案),当你可以通过用黄金比例近似结果在O(1)内完美地解决问题呢?虽然实际上我肯定会用以下形式编写:
def fib(nr):
ratio = (1 + math.sqrt(5)) / 2
return int(ratio ** nr / math.sqrt(5) + 0.5)
更高效,更易理解。
pow的时间复杂度为$O(\log(n))$。 - Sean Allred这是一个非递归的(匿名)记忆化一行代码
fib = lambda x,y=[1,1]:([(y.append(y[-1]+y[-2]),y[-1])[1] for i in range(1+x-len(y))],y[x])[1]
fib = lambda n, x=0, y=1 : x if not n else fib(n-1, y, x+y)
运行时间为O(n),斐波那契数列的前两个数字分别是0和1,从第三个数字开始,每个数字都是前两个数字之和...
我是Python的新手,但为了学习目的采取了一些措施。我收集了一些斐波那契算法并进行了一些措施。
from datetime import datetime
import matplotlib.pyplot as plt
from functools import wraps
from functools import reduce
from functools import lru_cache
import numpy
def time_it(f):
@wraps(f)
def wrapper(*args, **kwargs):
start_time = datetime.now()
f(*args, **kwargs)
end_time = datetime.now()
elapsed = end_time - start_time
elapsed = elapsed.microseconds
return elapsed
return wrapper
@time_it
def fibslow(n):
if n <= 1:
return n
else:
return fibslow(n-1) + fibslow(n-2)
@time_it
@lru_cache(maxsize=10)
def fibslow_2(n):
if n <= 1:
return n
else:
return fibslow_2(n-1) + fibslow_2(n-2)
@time_it
def fibfast(n):
if n <= 1:
return n
a, b = 0, 1
for i in range(1, n+1):
a, b = b, a + b
return a
@time_it
def fib_reduce(n):
return reduce(lambda x, n: [x[1], x[0]+x[1]], range(n), [0, 1])[0]
@time_it
def mm_fib(n):
return (numpy.matrix([[2, 1], [1, 1]])**(n//2))[0, (n+1) % 2]
@time_it
def fib_ia(n):
return pow(2 << n, n+1, (4 << 2 * n) - (2 << n)-1) % (2 << n)
if __name__ == '__main__':
X = range(1, 200)
# fibslow_times = [fibslow(i) for i in X]
fibslow_2_times = [fibslow_2(i) for i in X]
fibfast_times = [fibfast(i) for i in X]
fib_reduce_times = [fib_reduce(i) for i in X]
fib_mm_times = [mm_fib(i) for i in X]
fib_ia_times = [fib_ia(i) for i in X]
# print(fibslow_times)
# print(fibfast_times)
# print(fib_reduce_times)
plt.figure()
# plt.plot(X, fibslow_times, label='Slow Fib')
plt.plot(X, fibslow_2_times, label='Slow Fib w cache')
plt.plot(X, fibfast_times, label='Fast Fib')
plt.plot(X, fib_reduce_times, label='Reduce Fib')
plt.plot(X, fib_mm_times, label='Numpy Fib')
plt.plot(X, fib_ia_times, label='Fib ia')
plt.xlabel('n')
plt.ylabel('time (microseconds)')
plt.legend()
plt.show()
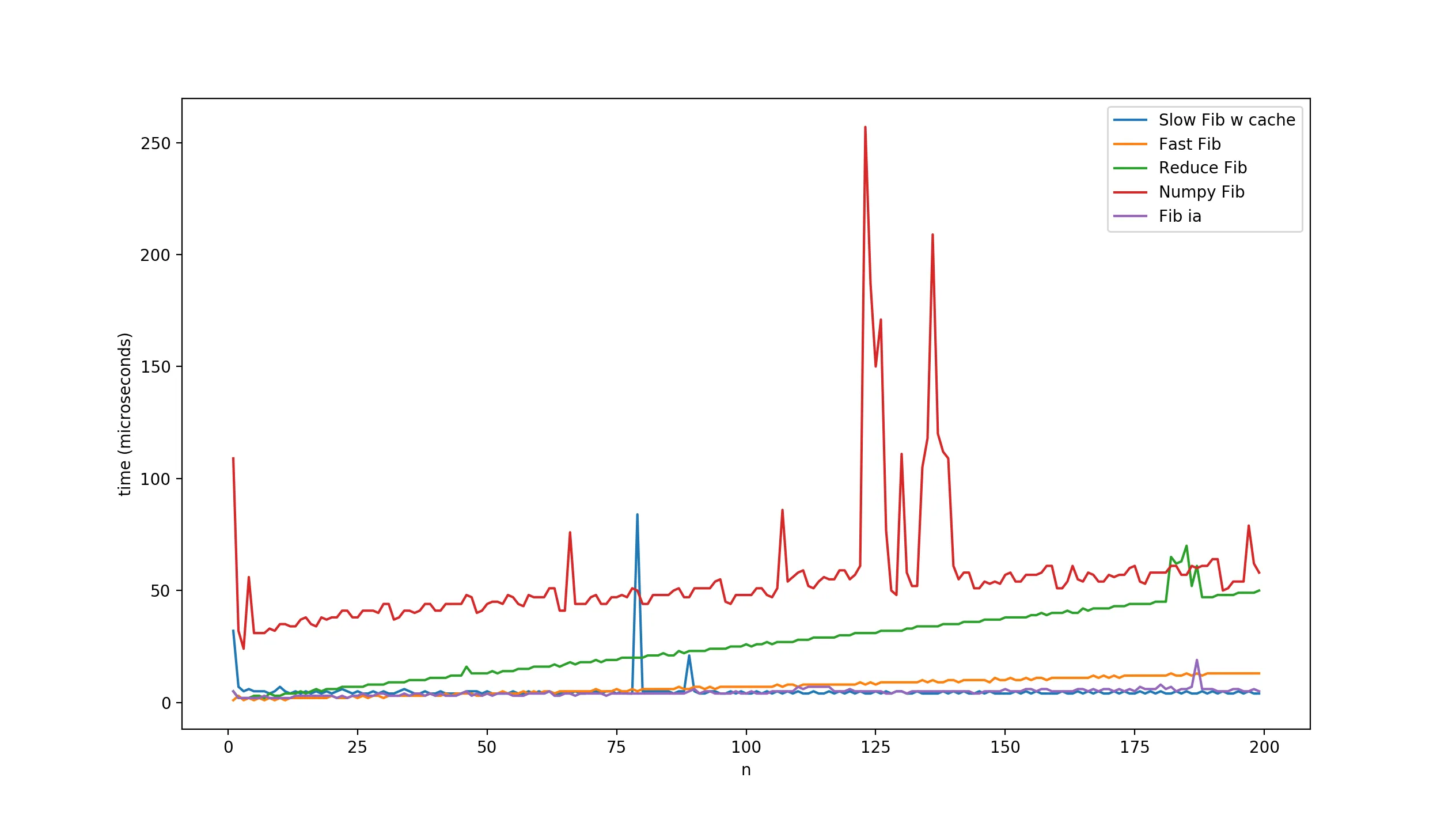 使用递归和缓存的Fiboslow_2,Fib整数算法和Fibfast算法似乎是最好的。也许我的装饰器不是衡量性能的最佳方法,但对于概述来说,它看起来很好。
使用递归和缓存的Fiboslow_2,Fib整数算法和Fibfast算法似乎是最好的。也许我的装饰器不是衡量性能的最佳方法,但对于概述来说,它看起来很好。我想看看是否可以创建整个序列,而不仅仅是最终值。
以下代码将生成长度为100的列表。它排除了前导的[0, 1],并且适用于Python2和Python3。没有其他额外的行!
(lambda i, x=[0,1]: [(x.append(x[y+1]+x[y]), x[y+1]+x[y])[1] for y in range(i)])(100)
输出
[1,
2,
3,
...
218922995834555169026,
354224848179261915075,
573147844013817084101]
还有一个例子,参考Mark Byers的答案:
fib = lambda n,a=0,b=1: a if n<=0 else fib(n-1,b,a+b)