参考信息:
- Python 3.8.3
- sklearn 1.0.2
我有一个scikit-learn pipeline,用于格式化一些数据,描述如下:
我像这样定义我的pipeline:
# Pipeline 1
cat_selector = make_column_selector(dtype_include=object)
num_selector = make_column_selector(dtype_include=np.number)
cat_linear_processor = OneHotEncoder(handle_unknown="ignore", drop='first', sparse=False)
num_linear_processor = make_pipeline(SimpleImputer(strategy="median", add_indicator=True), MinMaxScaler(feature_range=(-1,1)))
linear_preprocessor = make_column_transformer( (num_linear_processor, num_selector), (cat_linear_processor, cat_selector) )
model_params ={'alpha': 0.0013879181970625643,
'l1_ratio': 0.9634269882730605,
'fit_intercept': True,
'normalize': False,
'max_iter': 245.69684524349375,
'tol': 0.01855761485447601,
'positive': False,
'selection': 'random'}
model = ElasticNet(**model_params)
pipeline = make_pipeline(linear_preprocessor, model)
pipeline.steps 产生:
[('columntransformer',
ColumnTransformer(transformers=[('pipeline',
Pipeline(steps=[('simpleimputer',
SimpleImputer(add_indicator=True,
strategy='median')),
('minmaxscaler',
MinMaxScaler(feature_range=(-1,
1)))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x0000029CA3231EE0>),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore',
sparse=False),
<sklearn.compose._column_transformer.make_column_selector object at 0x0000029CA542F040>)])),
('elasticnet',
ElasticNet(alpha=0.0013879181970625643, l1_ratio=0.9634269882730605,
max_iter=245.69684524349375, normalize=False, selection='random',
tol=0.01855761485447601))]
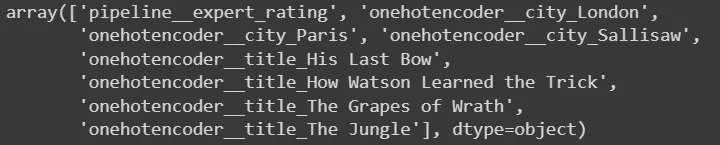
我想要做的是获取用于训练/测试的数据的特征名称。
我已经尝试参考了许多其他问题:
- Sklearn Pipeline:在ColumnTransformer中OneHotEncode后获取特征名称 - 使用Sklearn的变换器API,您能否始终跟踪列标签? - 使用ColumnTransformer.get_feature_names创建反向特征映射 然而,这些解决方案都没有奏效。例如:
[i for i in v.get_feature_names() for k, v in pipeline.named_steps.items() if hasattr(v,'get_feature_names')]
产生:
----> 1 [i for i in v.get_feature_names() for k, v in pipeline.named_steps.items() if hasattr(v,'get_feature_names')]
NameError: name 'v' is not defined
我尝试了:
pipeline[:-1].get_feature_names_out()
产出:
AttributeError: Estimator simpleimputer does not provide get_feature_names_out. Did you mean to call pipeline[:-1].get_feature_names_out()?
我该如何从当前流水线中检索编码后的特征名称呢?